
What is Databricks and how does it work?
Understand Databricks Lakehouse architecture, components like Delta Lake and Unity Catalog, real pricing, and how to get business value from your data.

.png)
If you've spent any time in data engineering or analytics circles, you've heard of Databricks. You've probably also noticed that explaining what it actually does is surprisingly hard. Ask five data professionals and you'll get five different answers: "It's a Spark platform." "It's a data lake." "It's like Snowflake but for ML." "It's... everything?"
That confusion is real, and it's not your fault. Databricks started as an Apache Spark company and has since grown into a full data analytics platform that spans ETL, SQL analytics, machine learning, and AI. The marketing calls it a "unified analytics platform," which is accurate but unhelpful if you're trying to build a mental model of what the product concretely does.
This article gives you that mental model. By the end, you'll understand Databricks' Lakehouse architecture, know how its key components fit together, have a realistic view of pricing, and see how it compares to Snowflake and BigQuery. You'll also learn how tools like OWOX help bridge the gap between Databricks and the business teams who actually need to use that data.
What is Databricks?
Before diving into architecture and components, let's start with the basics: what Databricks actually is, where it came from, and why even experienced data professionals struggle to pin it down.
The one-paragraph answer
Databricks is a cloud-based unified analytics platform built on the Lakehouse architecture. It combines the low-cost, flexible storage of a data lake with the performance and reliability of a data warehouse — all in one system. You can use it for data engineering, SQL analytics, machine learning, and AI workloads. It runs on AWS, Azure, and Google Cloud, and was founded by the original creators of Apache Spark, Delta Lake, and MLflow.
From Apache Spark to the Lakehouse
Databricks' story starts at UC Berkeley's AMPLab, where researchers created Apache Spark as a faster alternative to Hadoop's MapReduce. In 2013, those same researchers founded Databricks to build a commercial platform around Spark.
But the company didn't stop at Spark. Over the next decade, Databricks launched Delta Lake (a reliability layer for data lakes), MLflow (an open-source ML lifecycle tool), and Unity Catalog (centralized governance). Each addition solved a real gap — and each one made the platform harder to summarize in a sentence.
In 2020, Databricks introduced the "Lakehouse" concept: a single architecture that unifies data lakes and data warehouses. That's the core idea today. Everything Databricks builds — from SQL analytics to generative AI — sits on top of this Lakehouse foundation.
Why Databricks is hard to explain
The confusion happens because Databricks isn't one product — it's a platform of products. Think of it this way: Databricks is to data what AWS is to cloud infrastructure. AWS isn't "one thing" — it's compute, storage, networking, ML, and hundreds of services. Databricks works the same way, just scoped to data and AI.
The key to understanding Databricks is understanding its architecture. Once you see how the layers fit together, the individual features make sense.
How the Databricks Lakehouse architecture works
The Lakehouse is the idea that makes Databricks click. Instead of maintaining a cheap-but-messy data lake and a fast-but-expensive data warehouse side by side, you get one system that does both. Here's how the pieces fit together.
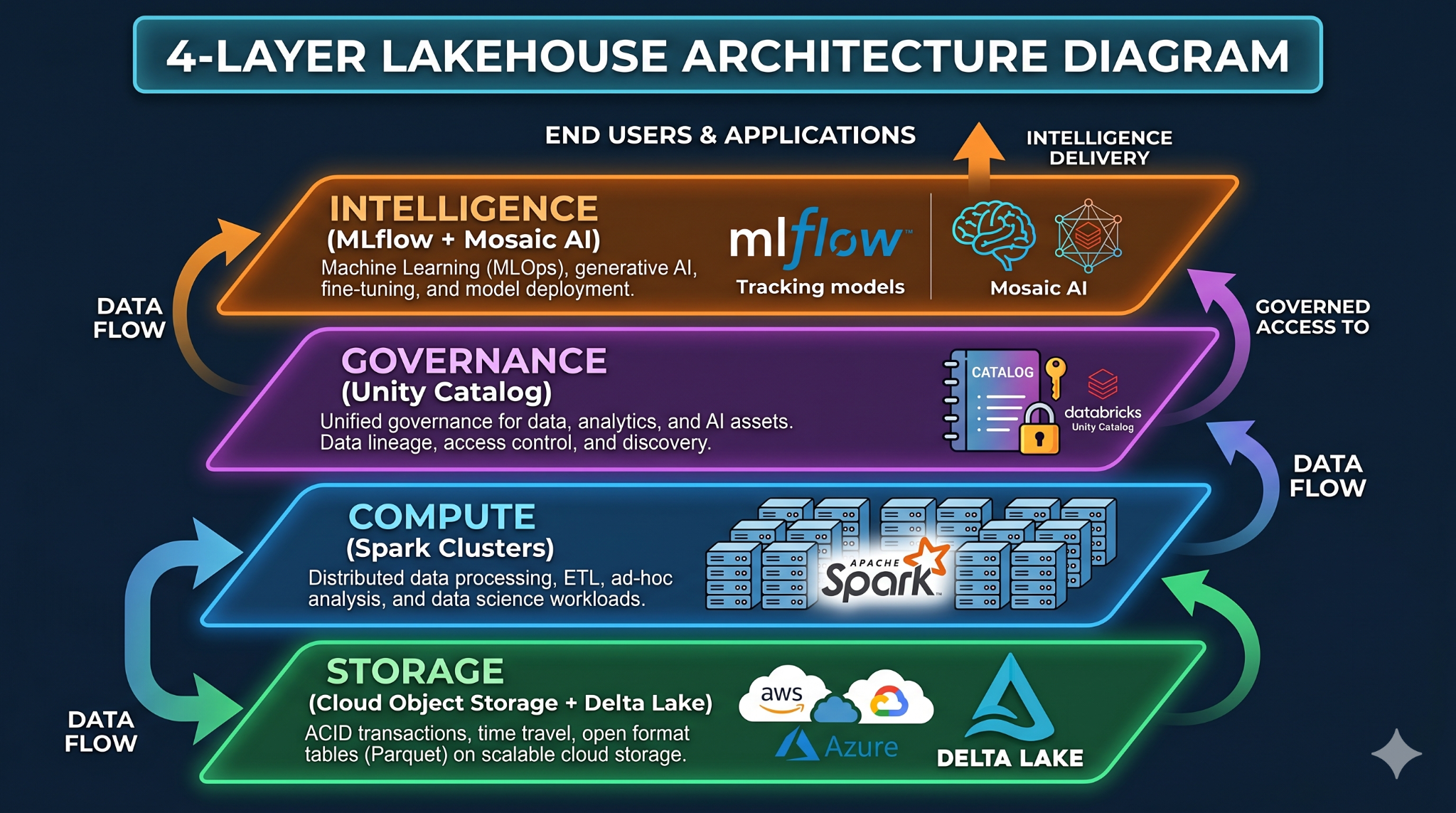
The 4 layers
The Lakehouse architecture organizes everything into four clean layers:
1. Storage layer. Your data lives in cloud object storage — Amazon S3, Azure Data Lake Storage, or Google Cloud Storage. Databricks doesn't store your data in a proprietary format. Instead, it uses Delta Lake (an open format built on Parquet files) to add structure, transactions, and versioning on top of commodity storage. This keeps costs low while maintaining reliability.
2. Compute layer. Apache Spark clusters handle processing. Databricks manages cluster provisioning, auto-scaling, and optimization so you don't have to manually tune infrastructure. Serverless options are available for SQL workloads, which removes cluster management entirely.
3. Governance layer. Unity Catalog provides centralized metadata management, fine-grained access control, data lineage tracking, and audit logging. This is what turns a raw data lake into a governed, trustworthy data platform.
4. Intelligence layer. MLflow for experiment tracking and model management, Mosaic AI for foundation model training and serving, and Databricks AI features that are embedded across the platform.
Delta Lake — The Foundation
Delta Lake is the storage format that makes the Lakehouse possible. It adds ACID transactions to Parquet files — the same reliability guarantees you expect from a traditional database, but running on cheap cloud object storage.
What this means in practice: you get schema enforcement (no more "surprise" columns breaking your pipelines), time travel (query any previous version of your data), and efficient upserts and deletes. Before Delta Lake, data lakes were "write once, read many" — you couldn't reliably update or delete records. Delta Lake fixed that.
Z-ordering and data skipping optimize query performance by organizing data physically on disk to match common query patterns. The result: data lake storage costs with data warehouse query speeds.
Unity catalog — governance and access control
Without governance, a data lake becomes a data swamp. Unity Catalog is Databricks' answer — a single place to manage access controls, track lineage, and audit who accessed what data and when.
Unity Catalog works across all Databricks workloads (SQL, notebooks, ML pipelines) and across clouds. You define permissions once and they apply everywhere. This matters because governance is the prerequisite for self-service analytics. If you can't control who sees what data, you can't safely let business teams explore it on their own — whether directly or through tools like OWOX Data Mart Management that expose governed data to spreadsheet users.
Key components of Databricks
Understanding the architecture is one thing. Knowing which tools you'll actually use day-to-day is another. Databricks packages its capabilities into four main product areas, each targeting a different workflow.
Databricks SQL
Databricks SQL is where the platform becomes relevant for data analysts, not just engineers. It provides a SQL-native interface with serverless compute, automatic query optimization, and direct connections to BI tools like Tableau, Looker, and Power BI.
For teams already using SQL for analytics, this is the entry point. You write familiar queries against governed data, and Databricks handles the compute. It competes directly with Snowflake and BigQuery for analyst workloads — and with OWOX's Databricks Connector to Google Sheets, you can push query results straight to spreadsheets for business reporting.
Databricks workflows
Workflows is Databricks' orchestration engine. You can schedule and monitor multi-step data pipelines — ingestion, transformation, ML training, reporting — all from one interface. For teams already on Databricks, it removes the need for a separate orchestration tool like Airflow.
MLflow and Mosaic AI
MLflow handles the ML lifecycle: experiment tracking, model versioning, model registry, and deployment. It's open-source and widely adopted beyond Databricks.
Mosaic AI extends this to foundation models — fine-tuning, serving, and evaluating large language models. This is Databricks' sharpest competitive edge: no other analytics platform offers end-to-end ML and AI capabilities this deeply integrated.
Delta Live Ttables
Delta Live Tables (DLT) is a declarative ETL framework. You define your transformations in SQL or Python, and Databricks handles orchestration, error handling, and data quality monitoring automatically. DLT is especially useful for streaming workloads — it unifies batch and real-time processing in one pipeline definition.
For teams building data marts or reporting layers, DLT simplifies the pipeline from raw data to business-ready datasets.
Common use cases for Databricks
Knowing what Databricks can do is different from knowing what teams actually use it for. In practice, most deployments fall into four categories, and many organizations use Databricks for several of them at once.
Data engineering and ETL
The most common use case. Teams use Databricks to build and orchestrate data pipelines — ingesting raw data from dozens of sources, transforming it through bronze/silver/gold layers (the medallion architecture), and making it query-ready.
Databricks is particularly strong here because of Delta Lake's reliability and Spark's processing power. If you're moving terabytes daily across complex transformation logic, Databricks handles it without breaking a sweat.
SQL analytics and BI reporting
With Databricks SQL, analysts can run queries directly against the Lakehouse without touching notebooks or Spark code. Connect your BI tool, write SQL, and build dashboards.
This is where Databricks overlaps most with Snowflake and BigQuery. The difference: Databricks gives you SQL analytics alongside ML and engineering workloads in one platform. And for teams that need reporting in Google Sheets rather than BI dashboards, OWOX connects natively to Databricks to deliver governed, refreshable reports.
Machine learning and AI
Train models on the same data you use for analytics — no export needed. MLflow tracks experiments, the model registry manages versions, and model serving deploys to production endpoints. Mosaic AI adds GenAI capabilities: fine-tune LLMs on your data, build RAG applications, and evaluate model quality.
This is Databricks' strongest differentiator. Snowflake and BigQuery offer ML features, but neither matches Databricks' depth.
Real-time streaming analytics
Spark Structured Streaming processes data as it arrives — fraud detection, IoT monitoring, real-time personalization. Delta Live Tables unify streaming and batch in one framework, so you don't maintain separate pipelines for real-time and historical data.
Databricks pricing — how it actually works
Pricing is where Databricks conversations get uncomfortable. The platform is powerful, but costs can spiral if you don't understand the billing model. Here's a practical breakdown.
The DBU model explained
Databricks pricing is consumption-based, measured in Databricks Units (DBUs). One DBU is a unit of processing capability per hour. The catch: DBU rates vary by workload type, tier, and cloud provider.
Here's how rates typically break down:
On top of DBU charges, you pay your cloud provider for the underlying VMs, storage, and networking. This dual-billing model means your total cost is Databricks fees + cloud infrastructure fees.
Note: these are approximate list rates. Actual pricing depends on your cloud provider, region, and negotiated contract.
What drives costs up (and how to control them)
Databricks can get expensive fast without discipline. The most common cost traps:
Always-on clusters. Interactive clusters left running overnight or on weekends burn DBUs with zero value. Fix: set auto-termination to 10-15 minutes of inactivity.
Over-provisioned compute. Bigger clusters don't always mean faster queries. Right-size your clusters and use serverless SQL for ad-hoc analytics.
Unoptimized queries. Full table scans on terabyte-scale Delta tables are expensive. Use partitioning, Z-ordering, and liquid clustering to keep queries efficient.
All-purpose compute for production jobs. All-purpose clusters cost 2-3x more than jobs compute. Run production ETL on jobs clusters, not interactive ones.
The best cost control strategy: use Unity Catalog's usage monitoring to track spending by team, project, and workload type. Visibility is the first step to optimization — the same principle behind OWOX's approach to data mart orchestration.
Databricks vs Snowflake vs BigQuery
If you're evaluating Databricks, you're almost certainly comparing it to Snowflake, BigQuery, or both. All three are strong platforms, but they're designed around different philosophies and excel at different things.
Where they overlap
All three platforms handle SQL analytics on structured data. All are cloud-native, support auto-scaling, and use consumption-based pricing. All connect to major BI tools. If your primary need is "run SQL queries on a large dataset and build dashboards," any of the three will work.
Where they diverge
The differences matter when your needs go beyond SQL analytics:
Choose Databricks if your team does heavy ML/AI alongside analytics, needs open formats, or runs complex multi-step data engineering pipelines.
Choose Snowflake if your primary workload is SQL analytics, you value simplicity, or you need cross-cloud data sharing. For a deeper comparison, see our guide on comparing data warehouses.
Choose BigQuery if you're already in the Google Cloud ecosystem, want true serverless (zero cluster management), or your analysts are the primary users. We cover BigQuery in depth in our BigQuery guides.
Regardless of which platform you choose, OWOX connects to all three — so your reporting layer stays consistent even if you switch warehouses.
How to get business value from Databricks data
Having a powerful data platform is only half the equation. The other half is getting insights out of it and into the hands of the people who make decisions every day. That's where most Databricks deployments hit a wall.
The reporting gap
Databricks is built for people who write code — data engineers, data scientists, analytics engineers. But the people who need insights the most — marketers, product managers, finance teams, executives — don't write SQL or Python. They use spreadsheets and dashboards.
This creates a reporting gap. The data is in Databricks, clean and governed. But getting it into the formats business teams actually use requires manual exports, one-off queries, or building custom pipelines. That's inefficient, error-prone, and doesn't scale.
How OWOX bridges Databricks to business reporting
OWOX connects to Databricks natively and solves this gap with data marts — reusable, governed datasets that analysts build once and business users consume on demand.
Here's how it works: an analyst writes the SQL logic that defines a data mart (revenue by channel, campaign performance, inventory metrics — whatever the business needs). OWOX runs that query against Databricks on a schedule, applies governance rules, and delivers the results to Google Sheets, Looker Studio, or other reporting tools.
Business users get fresh, trusted data in the tools they already know. No CSV exports. No waiting for the data team. No risk of someone running a bad query against production.
Building governed data marts on top of Databricks
The data mart approach works particularly well with Databricks because of Unity Catalog. Governance at the warehouse level (who can access what) combines with governance at the reporting level (what data is exposed, how it's transformed, when it refreshes).
This is the pattern we see working best: Databricks handles storage, compute, and governance. OWOX handles the last mile — turning raw warehouse data into business-ready reports that update automatically. For a deeper dive, see our guide on business reporting with data marts.
Getting started with Databricks
Ready to try Databricks? The barrier to entry is lower than you might think. Here's a practical starting point depending on your cloud environment and role.
Which cloud provider to choose
Databricks runs on all three major clouds. Your choice depends on your existing infrastructure:
AWS — the most mature Databricks deployment. Largest feature set, biggest community. Default choice for most teams.
Azure — deep Microsoft integration. Choose this if your organization runs on Microsoft 365, Active Directory, and Azure. "Azure Databricks" is a first-party Azure service with tighter billing and governance integration.
GCP — the newest option. Best for teams already using Google Cloud but wanting Databricks' ML and engineering capabilities alongside BigQuery.
All three are Cloud Edition deployments — Databricks manages the control plane while your data stays in your cloud account.
First steps for data analysts
If you're an analyst evaluating Databricks, start here:
- Begin with Databricks SQL, not notebooks. The SQL editor is familiar and doesn't require Spark knowledge.
- Learn Delta Lake basics. Understanding how your data is stored explains 80% of Databricks behavior.
- Understand cluster types. Know the difference between all-purpose, jobs, and serverless compute — it directly affects your costs.
- Set up Unity Catalog from day one. Retroactively adding governance is painful. Start governed and stay governed.
Resources and next steps
Explore the Databricks documentation and Databricks Academy for hands-on labs. For related reading on our blog, check out our guides on Lakehouse architecture, Lakehouse use cases, and data warehouse implementation.
Ready to build reports on top of Databricks? Start with OWOX — connect your Databricks workspace, build your first data mart, and deliver governed reports to Google Sheets in minutes.
Frequently asked questions
.png)


.png)



Finally, a tool that doesn't ask business users to learn a new dashboarding UI. Our marketing team already knows Sheets. OWOX just delivers the right data.
Joinable data marts concept was the thing that sold us. We can now use the semantic layer without building one.
Self-hosted the OSS version on Digital Ocean. Zero vendor lock-in. Contributed a Shopify connector back in week two.