
Databricks pricing explained: what impacts your bill?
Break down the dual-bill model, compare workload rates, and get a practical playbook to reduce Databricks costs by choosing the right compute types.

.png)
Teams across Reddit are sharing the same frustration: a $5,000+ monthly bill for a SQL warehouse alone, and nobody can explain to leadership where the money is going. The confusion is understandable. Databricks pricing isn't complicated in concept — it's consumption-based, like an electricity bill. But the details matter.
You're dealing with two separate bills (Databricks and your cloud provider), five different workload types with different rates, three pricing tiers that multiply costs, and a collection of cost traps that can quietly double your spend without anyone noticing.
This guide breaks down exactly how the Databricks bill is constructed, what drives costs up, and how to bring them down. Whether you're evaluating Databricks for the first time or trying to defend your current spend to a CFO, this is the pricing breakdown you need.
How Databricks pricing actually works
Before diving into specific rates and tiers, you need to understand the fundamental structure of a Databricks bill — because it's not one bill, it's two. This dual structure is the single biggest source of confusion for teams trying to predict or control their Databricks costs.
The dual-bill model — DBU charges + cloud infrastructure
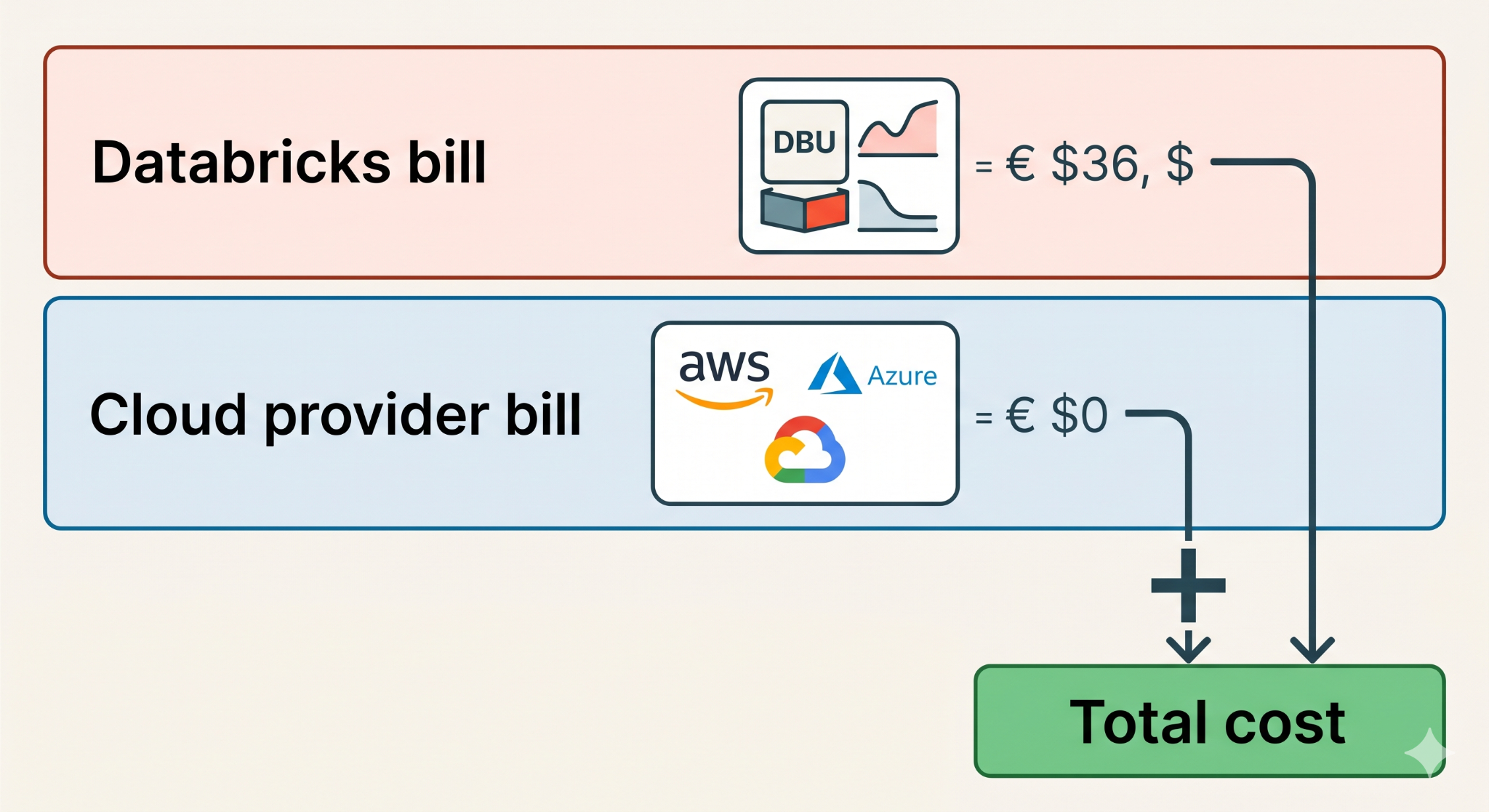
Databricks charges you for compute in DBUs (Databricks Units). Your cloud provider — AWS, Azure, or GCP — separately charges you for the virtual machines, storage, and networking that those DBUs run on. Your total Databricks cost is always the sum of both:
Total cost = Databricks DBU fees + cloud infrastructure fees
This dual-bill model is why predicting Databricks costs is harder than with Snowflake or BigQuery, which bundle compute and infrastructure into a single price. With Databricks, you can optimize the DBU side but still get surprised by the cloud infra side — or vice versa.
What is a DBU (Databricks Unit)?
A DBU is a normalized unit of processing power per hour. It's not tied to a specific VM size. Databricks normalizes compute consumption across instance types so billing stays comparable regardless of which machines are running underneath. One DBU on a small instance and one DBU on a large instance represent the same billing unit, even though the raw compute power differs. Think of it as Databricks' universal currency for measuring how much processing you consumed.
Pay-as-you-go vs committed use discounts
Databricks offers two purchasing models. Pay-as-you-go charges per second with no commitment — you pay list price for exactly what you use. Committed use (also called Databricks Commit) lets you pre-purchase DBUs at a discount, typically 20–40% savings, for 1–3 year terms.
The decision is straightforward: commit when you have stable production workloads with predictable consumption patterns. Stay on pay-as-you-go when you're an early-stage team still figuring out usage, or when workloads are too variable to forecast accurately.
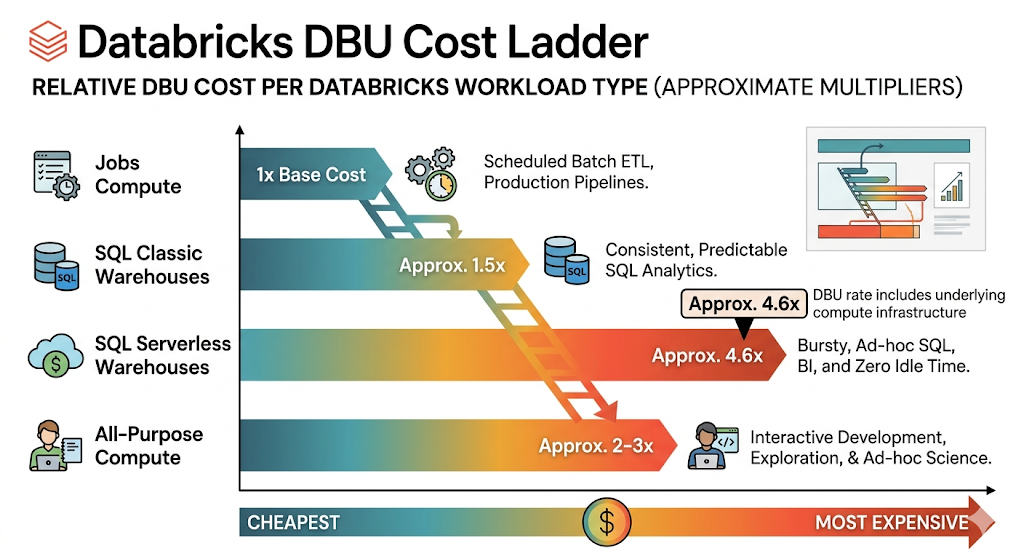
Databricks workload types and their DBU rates
Not all Databricks compute costs the same. The workload type you choose is the single biggest factor in your bill — the same work can cost 2–3x more on the wrong compute type. Understanding this is also where tools like OWOX become valuable: when you can attribute spend to specific workload types and teams, you can spot mismatches before they become expensive habits.
Jobs compute
The cheapest option. Jobs compute is designed for scheduled ETL, batch processing, and production pipelines — anything that runs on a schedule without a human sitting in front of it. There's no interactive notebook access, which is exactly why it's cheaper. If your workload doesn't need real-time interaction, it should be on jobs compute.
All-purpose compute
The most expensive workload type. All-purpose compute powers interactive notebooks, development environments, and ad-hoc exploration. It costs 2–3x more than jobs compute for equivalent processing. The number one cost trap in Databricks: teams running production workloads on all-purpose clusters because they originally developed the code there and never migrated it to jobs compute.
SQL warehouses
Optimized for SQL analytics and BI tool connections. SQL warehouses come in two flavors: Classic (you manage the clusters) and Serverless (Databricks manages everything). Serverless costs more per DBU but eliminates cluster management overhead and idle costs — you only pay when queries are actually running.
Serverless compute
Databricks manages everything — no clusters to configure, no auto-scaling to tune, no idle VMs burning budget. Serverless is available for SQL, notebooks, and jobs. The per-DBU rate is higher, but you pay zero idle cost and get faster startup times. Best for ad-hoc analytics, variable workloads, and teams without dedicated platform engineers.
Model serving and specialized workloads
Foundation model serving, vector search, and other AI/ML workloads have their own DBU rates. These tend to be the most expensive per-DBU but serve specialized use cases where the value per computation is highest.
Note: Rates shown are approximate list prices for AWS (US regions) as of 2026. Azure and GCP rates differ slightly. Always check the official Databricks pricing page for current rates. These are DBU charges only — cloud infrastructure costs are additional.
Databricks pricing tiers — Standard vs Premium vs Enterprise
Databricks offers three pricing tiers that unlock progressively more features — but they also increase your per-DBU rates. Choosing the right tier is a balance between capability needs and cost.
What each tier includes
Standard gives you core Databricks features with basic security. It's the cheapest per-DBU but lacks governance features most teams need as they scale.
Premium adds Unity Catalog (centralized data governance), fine-grained access control, audit logging, and advanced workflow features. This is where most production teams land.
Enterprise adds compliance certifications (HIPAA, FedRAMP, SOC 2 Type II), enhanced security controls, and advanced governance capabilities. It carries the highest per-DBU premium.
Which tier should you choose?
Most teams should start with Premium. Unity Catalog — Databricks' governance layer — is Premium-only and essential for any team with more than a few users. Without it, you can't enforce column-level security, track data lineage, or audit who accessed what. Standard saves money per DBU but locks you out of the governance features that prevent much larger costs downstream (like compliance violations or uncontrolled data sprawl).
Enterprise is only justified if you have specific compliance requirements — HIPAA for healthcare data, FedRAMP for government contracts, or similar regulated workloads. Don't pay the Enterprise premium for features you won't use.
Databricks pricing by cloud provider
Databricks runs on AWS, Azure, and GCP, and prices aren't identical across clouds. The DBU rates from Databricks stay relatively consistent, but the cloud infrastructure costs — that second bill — can vary significantly depending on your provider.
AWS pricing
AWS is the most mature Databricks deployment. You get standard DBU rates and infrastructure costs follow standard EC2/S3 pricing. The biggest cost lever on AWS is spot instances for jobs compute — using spot can reduce infrastructure costs by 60–80% on batch workloads, though with the risk of interruption.
Azure Databricks pricing
Azure Databricks is a first-party Azure service, meaning billing flows through your Azure subscription and shows up alongside your other Azure resources. DBU rates are slightly different from AWS. The key benefits: unified billing across your Azure estate, and Azure Reserved Instance discounts apply to the underlying VMs that power your Databricks clusters.
GCP pricing
GCP is the newest Databricks deployment option. Competitive DBU rates, with preemptible VMs available for cost savings on batch jobs. GCP's sustained-use discounts automatically reduce VM costs as usage increases, which can meaningfully lower the infrastructure portion of your bill.
Why prices differ across clouds
The Databricks DBU rate is set by Databricks and stays broadly consistent across clouds. But the cloud infrastructure cost — the second bill — varies based on each provider's VM pricing, regional availability, storage rates, and marketplace agreements. This is why a true cross-cloud cost comparison requires looking at both the DBU layer and the infrastructure layer together. A region with cheaper DBU rates might have more expensive VMs, making the total cost higher.
What actually drives your Databricks bill up
Understanding rates and tiers is one thing. Understanding why your actual bill is higher than expected is another. These are the cost drivers that catch most teams — and each one has a specific fix.
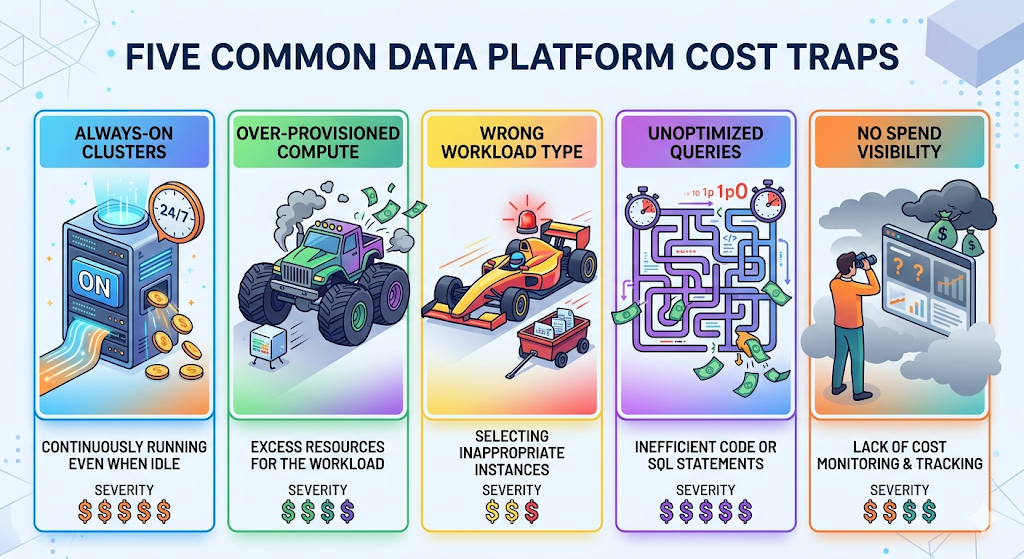
Always-on clusters
Interactive clusters left running overnight, on weekends, and during holidays. Each hour burns DBUs even if nobody is querying. This is the most common cost trap for mid-size teams. A single all-purpose cluster with 8 workers running 24/7 can cost $3,000–5,000/month in DBUs alone — before cloud infrastructure costs.
Over-provisioned compute
Autoscaling max set too high, or manual cluster sizes chosen "to be safe." More workers means more DBUs means a higher bill. Most ad-hoc queries and development notebooks don't need 16-node clusters. Teams often provision for peak load and forget to scale back, paying for capacity they rarely use.
Wrong workload type for the job
Running production ETL on all-purpose compute instead of jobs compute. Running scheduled reports on interactive clusters instead of serverless SQL. Every mismatched workload is paying a 2–3x premium for compute features it doesn't need. This is the most common hidden cost multiplier we see across teams.
Unoptimized queries and storage
Full table scans on terabyte-scale Delta tables. Missing partitioning, no Z-ordering, no liquid clustering. A query that runs for 10 minutes when it could run in 30 seconds — that's a 20x cost difference in DBU consumption. Storage costs compound this: unbounded time travel retention on large tables means you're paying to store every historical version of data you may never access again.
Lack of visibility into team-level spend
Without cost attribution, nobody owns the bill. Teams can't see what they're spending, so they can't optimize. Unity Catalog tracks usage data, but the data only becomes actionable when you build reports that surface it to the right people. This is where OWOX data marts come in — connect your Databricks usage data and deliver team-level cost reports to Google Sheets where finance and engineering leads can review them weekly, without asking the data team for a custom pull every time.
How to reduce your Databricks costs
Every cost driver from the previous section has a specific fix. Here's the optimization playbook, ordered by impact.
Right-size clusters and use autoscaling wisely
Set auto-termination to 10–15 minutes on all interactive clusters. Use single-node clusters for development and notebook exploration. Set autoscaling minimum to 1 and maximum to what you actually need based on historical usage — not what "might" be needed on the busiest day of the quarter.
Use serverless SQL for ad-hoc analytics
Zero idle cost, instant startup. Serverless SQL costs more per DBU but is cheaper in practice because you're not paying for idle clusters between queries. Best for analyst teams with unpredictable query patterns who don't need a dedicated cluster running all day.
Move production jobs off all-purpose compute
Schedule ETL and production pipelines on jobs compute, which costs 2–3x less than all-purpose. Use Databricks Workflows for orchestration. This single change often cuts the biggest chunk off the bill — we've seen teams save 40–60% on their Databricks DBU costs just by moving production workloads to the right compute type.
Optimize Delta Lake storage
Use Z-ordering on frequently filtered columns to reduce scan volume. Enable liquid clustering for new tables. Compact small files with the OPTIMIZE command. Set retention policies to avoid unbounded time travel storage — 7 days is sufficient for most production tables, and the default of 30 days can mean terabytes of unnecessary historical data.
Monitor spend with governed reporting
Build cost dashboards that attribute spend to teams, projects, and workload types. Unity Catalog tracks the usage data you need, but the reporting layer matters just as much as the data itself. With OWOX, you can pipe Databricks usage data into governed data marts and deliver cost reports directly to Google Sheets — where finance teams, engineering managers, and leadership can review spend weekly without requiring SQL access or a BI tool license.
BANNER: <div class="insert-html" data-url="addon-databricks-phd"></div>
Databricks pricing vs Snowflake vs BigQuery
If you're comparing Databricks costs to alternatives, you need to understand that these platforms bill differently — and a raw per-unit comparison doesn't tell the full story.
How the billing models compare
Databricks charges in DBUs plus cloud infrastructure — two separate bills. Snowflake charges in credits that bundle compute and infrastructure into one price. BigQuery offers on-demand per-TB scanning or flat-rate slot reservations — both as a single bill.
The dual-bill model makes Databricks harder to predict but potentially cheaper for teams that optimize their cloud infrastructure aggressively (using spot instances, reserved VMs, right-sized instances). Snowflake's single-bill simplicity is easier to budget. BigQuery's on-demand pricing works well for sporadic, query-heavy workloads but can get expensive at scale.
For a detailed platform comparison covering architecture, performance, and use cases, see our data warehouses comparison guide.
Total cost of ownership considerations
Raw per-unit pricing only tells part of the story. When evaluating total cost of ownership, consider where each platform excels: Databricks wins on ML/AI workloads with native notebook support and MLflow integration. Snowflake wins on data sharing and cross-cloud replication. BigQuery wins on GCP-native simplicity and serverless-by-default architecture.
Also factor in operational costs: Databricks requires more platform engineering to manage clusters and optimize costs. Snowflake and BigQuery abstract more of that away but give you less control over the underlying infrastructure. Teams with strong platform engineering tend to get better economics from Databricks; teams without prefer the operational simplicity of Snowflake or BigQuery.
How to estimate your Databricks bill
Whether you're evaluating Databricks for the first time or trying to forecast next quarter's spend, here's how to build a realistic cost estimate.
Using the Databricks pricing calculator
The Databricks pricing calculator lets you estimate DBU costs based on cloud provider, region, workload type, and cluster configuration. Input your expected compute hours and instance types to get a DBU cost estimate. Important caveat: the calculator estimates DBU costs only — you still need to add cloud infrastructure costs (VMs, storage, networking) from your cloud provider's own pricing calculator.
Real-world monthly cost scenarios
These ranges include both DBU and estimated cloud infrastructure costs:
Small team (5–10 analysts, light SQL + notebooks): $1,500–3,000/month. Mostly serverless SQL for ad-hoc queries, one small all-purpose cluster for development.
Mid-size production (20+ users, daily ETL + SQL analytics): $8,000–15,000/month. Jobs compute for production pipelines, serverless SQL for analyst queries, one or two all-purpose clusters for data engineering.
Enterprise with ML (50+ users, ML training + serving + ETL): $25,000–50,000+/month. Heavy jobs compute, model serving endpoints, multiple all-purpose clusters, SQL warehouses for BI.
These are ranges, not guarantees — your actual costs depend on data volumes, query complexity, cluster configurations, and how well you optimize.
Building cost visibility with OWOX
The fastest path from "we don't know what we're spending" to "we control what we're spending" is governed reporting. OWOX connects to Databricks natively and lets you build data marts that pull usage and cost data into structured, refreshable reports. Deliver cost breakdowns by team, workload type, and project directly to Google Sheets — where finance and leadership can check spend weekly without asking the data team for a custom analysis.
Conclusion
Databricks pricing comes down to two bills (DBU charges + cloud infrastructure), five workload types with dramatically different rates, and three pricing tiers. The bill is controllable — but only if you choose the right compute types for each workload, right-size your clusters, and build visibility into what each team is actually spending.
The most common mistake isn't choosing the wrong tier or the wrong cloud. It's running workloads on the wrong compute type (all-purpose instead of jobs) and leaving clusters running when nobody's using them. Fix those two things first, and you'll likely cut 30–50% off your current bill.
For teams that want cost reports delivered automatically without building custom dashboards, OWOX connects to Databricks natively and turns usage data into business-ready reporting through governed data marts.
For a deeper look at what Databricks is and how its architecture works, read our guide on what is Databricks.
Frequently asked questions
.png)

.png)




Finally, a tool that doesn't ask business users to learn a new dashboarding UI. Our marketing team already knows Sheets. OWOX just delivers the right data.
Joinable data marts concept was the thing that sold us. We can now use the semantic layer without building one.
Self-hosted the OSS version on Digital Ocean. Zero vendor lock-in. Contributed a Shopify connector back in week two.