
What is OKF (Open Knowledge Format)? Google's new data standard, explained
The Open Knowledge Format in plain English — plus a free, open-source way to author it visually and export it.

.png)
On June 12, 2026, Google Cloud's Data Cloud team published a new open specification called the Open Knowledge Format (OKF) – and unless you follow data infrastructure closely, you probably missed it. You shouldn't have.
OKF is Google's bet on a simple, slightly radical idea: the metadata and context your data (and your AI agents) depend on shouldn't be locked inside a proprietary catalog. It should be "just markdown, just files, just YAML frontmatter" – portable, readable by humans, and parseable by machines, with no SDK and no runtime required.
Andrej Karpathy, quoted in Google's announcement, summed up why the timing clicks: "LLMs don't get bored, don't forget to update a cross-reference, and can touch 15 files in one pass. The bookkeeping that causes humans to abandon personal wikis is exactly what LLMs are good at."
Here's what OKF actually is, why it matters, and how to build one in about two minutes.
.gif)
The problem OKF is trying to fix
Every data team has the same quiet crisis: the knowledge about your data is scattered everywhere except where you need it. It lives in a metadata catalog behind a proprietary API, in a half-updated wiki, in dbt docs, in code comments and notebook cells – and, inevitably, in the heads of two senior engineers who are always in meetings.
That was annoying when humans were the only consumers. It's now a real bottleneck, because AI agents need that context to be useful. Ask an LLM to write a query against your warehouse and it has to reconstruct, from scratch, what your tables mean, how they join, and which column is the real revenue number. Today every agent builder solves that from scratch, and every vendor reinvents the same data model. The knowledge stays trapped in whatever system created it.
OKF's answer isn't another service. It's a format – one that anyone can produce without an SDK, anyone can consume without an integration, and that survives moving between systems, organizations, and tools. Google's own framing is "knowledge as a living wiki": a body of curated markdown that teams manage like code and agents read and update on their own.
What an OKF document actually looks like
This is the part that surprises people. There's no schema language to learn, no binary, no special tooling. An OKF knowledge base is a folder of markdown files with YAML frontmatter. One concept per file. Here's a single table, described in OKF:
---
type: BigQuery Table
title: Orders
description: One row per completed customer order.
resource: https://console.cloud.google.com/bigquery?p=acme&d=sales&t=orders
tags: [sales, revenue]
timestamp: 2026-05-28T14:30:00Z
---
# Schema
| Column | Type | Description |
|--------|------|-------------|
| `order_id` | STRING | Globally unique order identifier. |
| `customer_id` | STRING | FK to [customers](/tables/customers.md). |
# Joins
Joined with [customers](/tables/customers.md) on `customer_id`.A few things to notice, because they're the whole design:
- The only required frontmatter field is type. Everything else (title, description, resource, tags, timestamp) is optional and producer-defined. The spec is deliberately minimally opinionated – it defines just enough to be interoperable, not how you must model your world.
- Relationships are just markdown links. [customers](/tables/customers.md) ties this table to another concept. A foreign key, a join, a "see also" – all the same primitive. Cross-link enough documents and you get a navigable graph of your data.
- Files live in a directory tree (datasets/, tables/, metrics/…), and optional index.md / log.md files give a human-friendly table of contents and a changelog.
That's it. It reads fine in a text editor, diffs cleanly in a pull request, and an LLM can both read it and write it.
OKF Format, NOT a platform
The most important word in the announcement is not.
OKF is not tied to a cloud, a database, a model provider, or an agent framework. Google calls this "format, not platform," and they back it up with three principles:
(1) Minimally opinionated – the spec defines the interoperability surface, not your content model.
(2) Producer/consumer independence – knowledge can be written by a human, generated by a pipeline, or synthesized by an LLM, and consumed by anything that can read markdown.
(3) No lock-in, ever – it will never require a proprietary account or SDK. (just like we state for OWOX Data Marts)
Google has updated its own Knowledge Catalog to ingest OKF and serve it to agents, and they shipped reference implementations: an enrichment agent that walks BigQuery datasets and drafts OKF docs, a static HTML visualizer that renders a bundle as an interactive graph, and three sample bundles you can read today – GA4 e-commerce, Stack Overflow, and Bitcoin public datasets.
But they're explicit that adoption beyond Google products is the point: "Contributions, alternative implementations, and adoption beyond Google products are all explicitly welcomed."
Or, as they put it: "Whatever shape your knowledge takes today, OKF is designed to be the lingua franca it can be exchanged for tomorrow."
Why this is a bigger deal than "another spec"
It's worth being skeptical – the data world is a graveyard of formats nobody adopted. But OKF has a few things going for it that most didn't:
- It's boring on purpose. Markdown + YAML is the lowest-friction format imaginable. There's nothing to install and nothing to learn, which is exactly why conventions like AGENTS.md and CLAUDE.md, Obsidian vaults, and "metadata-as-code" repos already caught on. OKF formalizes that same instinct for data.
- It rides the agent wave instead of fighting it. The pitch isn't "humans, please maintain a wiki." It's "let the agents do the bookkeeping you always hated, and you curate." That's the Karpathy point, and it's the right bet for where tooling is going.
- A major vendor seeded it with real tooling and samples, then explicitly opened the door to the ecosystem. Standards win when they're easy to adopt and someone shows up first.
The catch – and the easy way around it
Here's the honest tension. OKF is wonderful for machines and for git. It is tedious for a human to author by hand. Getting the frontmatter right, keeping join links pointed at the correct files, laying out a sensible directory tree – it's fiddly, exactly the kind of bookkeeping the Karpathy quote is about. Google shipped a great way to view OKF (the static visualizer). It's a read-only viewer, though – not an editor.
That's the gap we built OWOX Model Canvas to fill: a free, open-source visual editor for data models in the Open Knowledge Format.
Draw it, or describe it. Sketch your marts and joins on a canvas – or type a sentence ("we're an e-commerce shop with customers, orders, and products") and let Claude, ChatGPT, or Gemini draft the model for you.
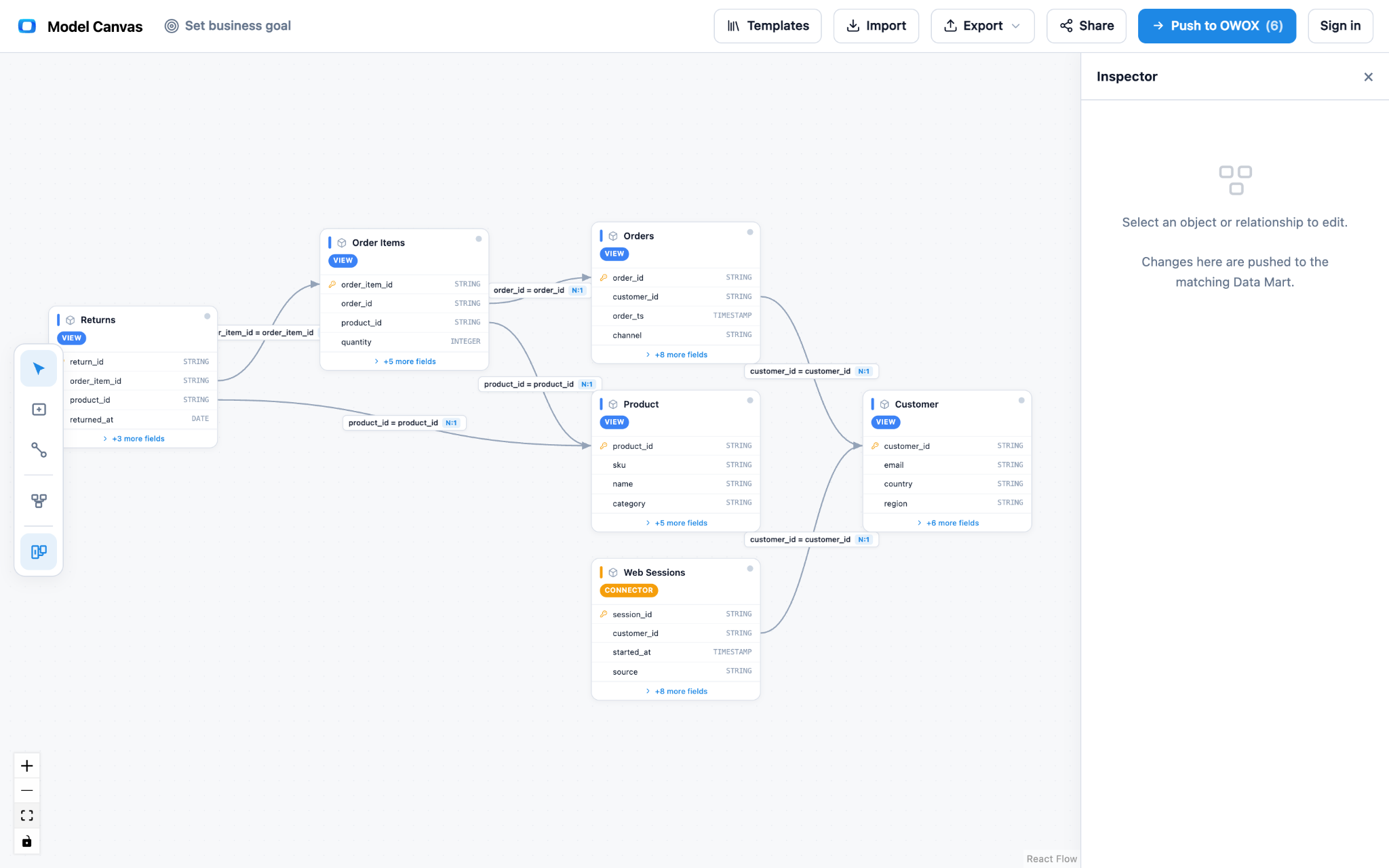
See it as a real ERD. Field-level tables, primary keys, join keys, cardinality – not just boxes.
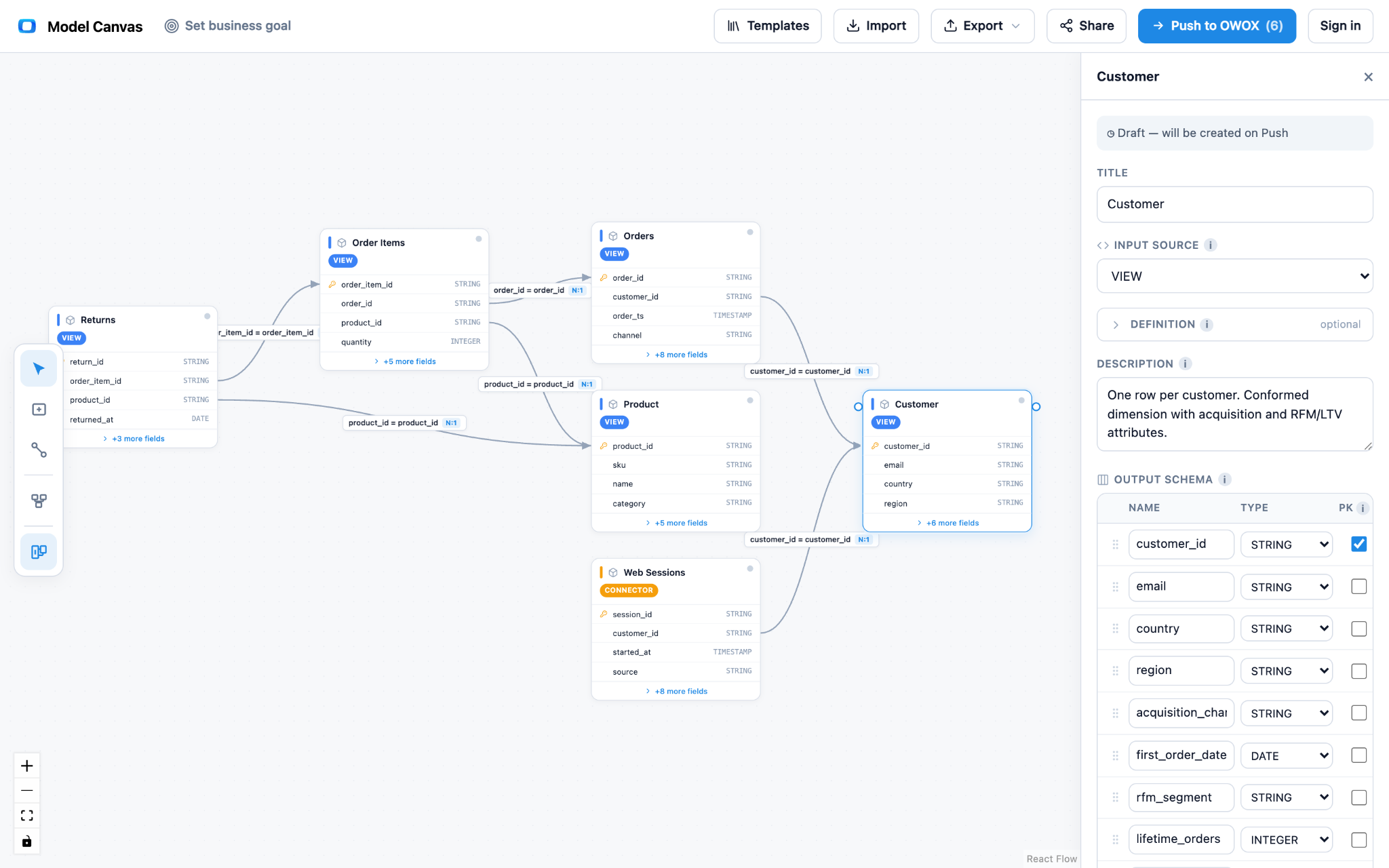
Export portable OKF. Your model leaves as a markdown bundle you own, in any git repo. No lock-in, by design – the same property OKF is built around.
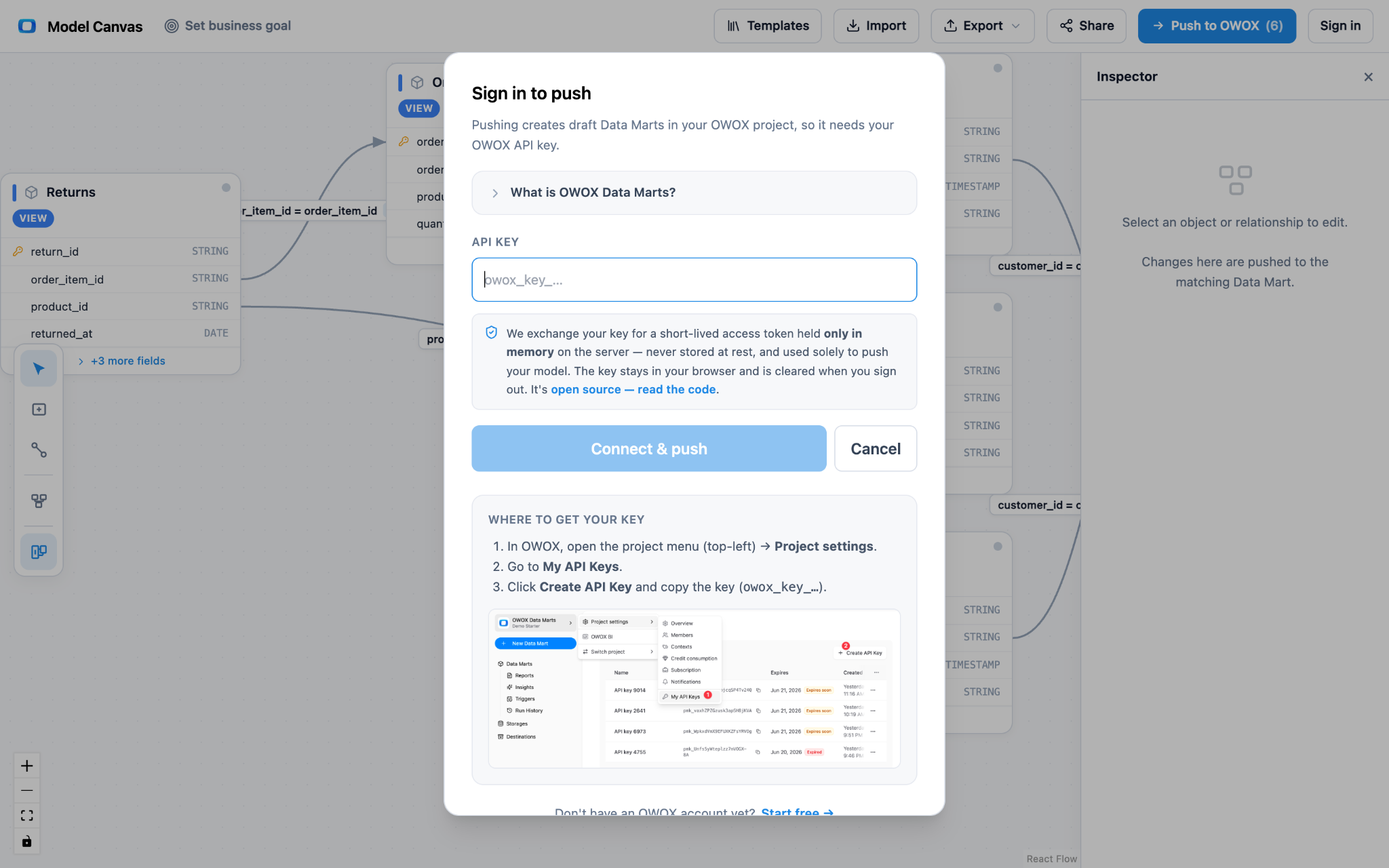
Push it live (optional). When you're ready, push the model into OWOX Data Marts as drafts in one click. That part needs an OWOX API key; everything else is anonymous and needs no sign-in.
Full disclosure: we're OWOX, a Google Cloud Partner for over a decade.
We're not on Google's OKF team – we just got excited about the format and built the editor we wanted. It's free, it works in your browser, and it's open source, so you can read exactly what it does (or self-host it).
Try it in two minutes
- Open model.owox.com – no sign-up required and it’s free.
- Pick a template or describe your data and let AI draft a model.
- Tidy it on the canvas, then Export → OKF. That's a portable Open Knowledge Format bundle, authored visually.
Further reading
- Google's announcement: How the Open Knowledge Format can improve data sharing (Google Cloud blog, June 12, 2026)
- The spec and samples: GoogleCloudPlatform/knowledge-catalog
- Author OKF visually, free: model.owox.com
Frequently asked questions







Finally, a tool that doesn't ask business users to learn a new dashboarding UI. Our marketing team already knows Sheets. OWOX just delivers the right data.
Joinable data marts concept was the thing that sold us. We can now use the semantic layer without building one.
Self-hosted the OSS version on Digital Ocean. Zero vendor lock-in. Contributed a Shopify connector back in week two.