
How to connect BigQuery MCP to Claude (and why it hallucinates your joins)
Tutorial: connect BigQuery to Claude via MCP, fix real bugs, then discover why Anthropic's own team says raw warehouse access isn't enough.


BigQuery MCP promises a direct line from Claude to your warehouse. Ask a question, get SQL, see results – all without leaving the chat window. The setup takes about 30 minutes. The first query feels like magic.
Then the magic breaks.
The OAuth flow throws redirect_uri_mismatch. A missing IAM role causes Claude to fabricate an entire report instead of throwing an error.
And even when everything connects perfectly, Claude writes its own SQL against your raw tables – picking join keys that look right but aren’t, inventing metrics that sound plausible but are off by double digits.
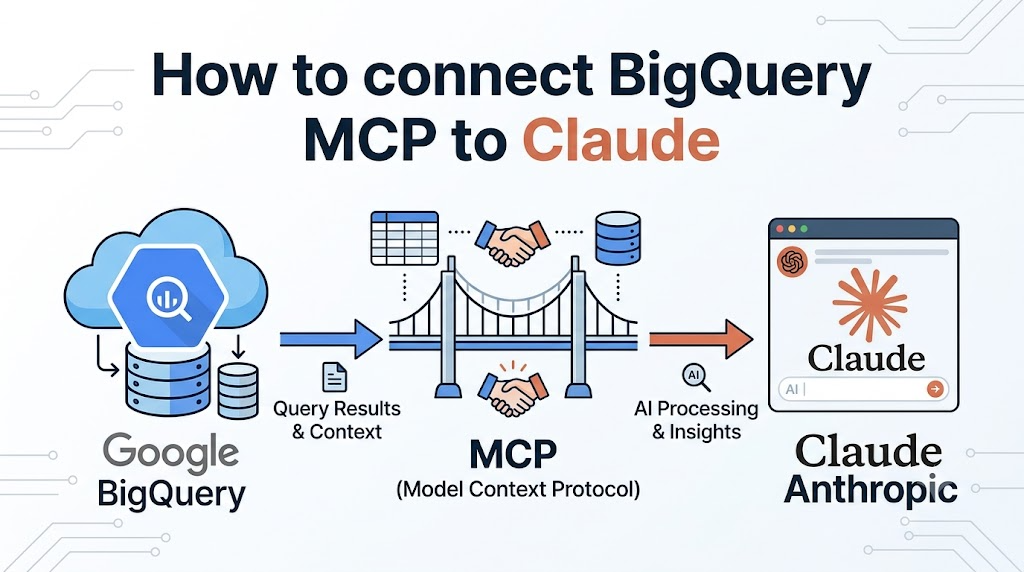
This article covers the full setup (both Google’s remote server and the community package), the bugs you’ll actually hit, and the architectural problem nobody else on SERP is talking about: Anthropic’s own data team published numbers showing 21% accuracy when Claude queries raw warehouse tables without a context layer. Twenty-one percent. The model maker themselves confirmed that raw MCP access isn’t enough.
We’ll show you how to set it up anyway – because we use it ourselves - for ad-hoc exploration, it’s useful. And then we’ll show you what to do when you need numbers the board can actually trust.
What BigQuery MCP actually gives you
Before diving into setup, it helps to understand exactly what BigQuery MCP exposes – and what it doesn’t.
The six tools
MCP (Model Context Protocol) connects Claude directly to your BigQuery warehouse. The BigQuery MCP server exposes six tools:
- list_dataset_ids – returns all dataset names in the project
- list_table_ids – lists tables within a dataset
- get_dataset_info – metadata about a dataset (location, labels, description)
- get_table_info – full schema for a table (column names, types, descriptions)
- execute_sql – runs arbitrary SQL and returns results
- execute_sql_readonly – same, but blocks any write operations (INSERT, UPDATE, DELETE, DDL)
That’s it. No materialized views. No stored procedures. No access to Google Drive external tables. Results are capped at 3,000 rows per query, with a 3-minute timeout. At least as of today: June 09, 2026.
What this means in practice
This is a raw SQL interface. Claude sees your schema, writes its own queries, and runs them. There’s no business context layer, no metric definitions, no governed join logic. Claude interprets column names literally and guesses how tables relate to each other.
That’s powerful for quick exploration – and, as we’ll see, dangerous for anything that needs to be accurate.
How to set up BigQuery MCP for Claude
Two paths – Google’s official remote server or a community MCP package. Here’s both.
Prerequisites
You need a GCP project with the BigQuery API enabled. The identity that authenticates (whether your Google account or a service account) needs three IAM roles:
- BigQuery Data Viewer – read access to tables and views
- BigQuery Job User – permission to run queries
- MCP Tool User (for the remote server) or Dataplex Catalog Viewer (for community servers) – this is the one most tutorials miss
That third role is critical. Without it, the connection appears to work but Claude can’t actually read your data. We’ll cover what happens in that case in the next section.
Option A – Google’s remote MCP server
Google hosts a remote MCP server at https://bigquery.googleapis.com/mcp.
The first path is to use the direct connector. Go to Claude → Customize → Connect apps → Select Google Cloud BigQuery.
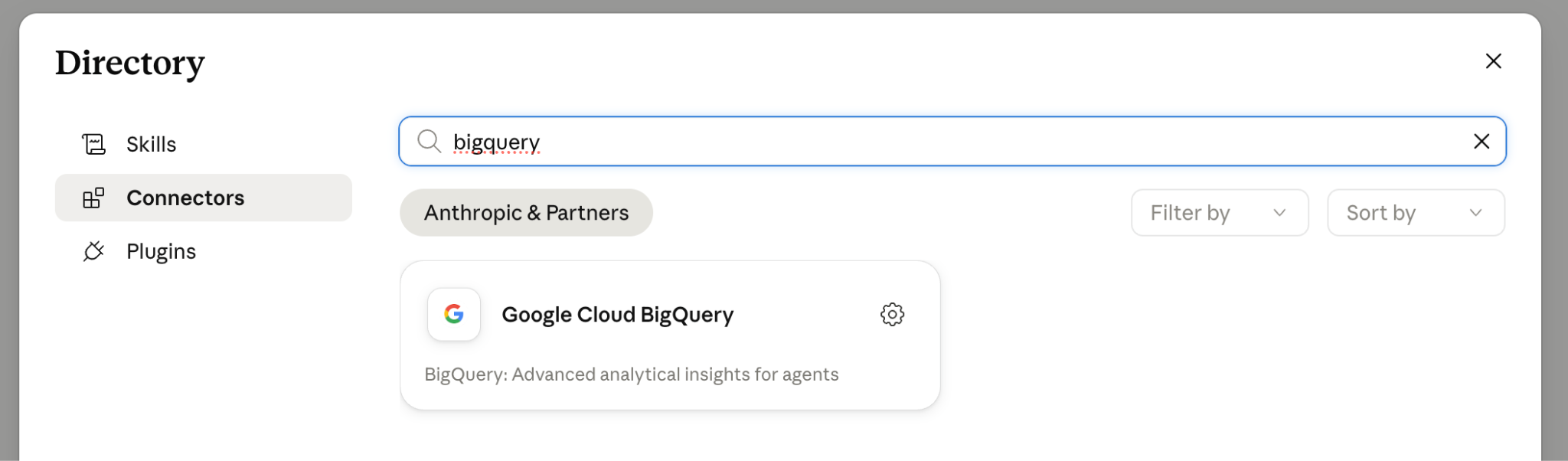
You’ll then need to go to the Google Cloud Console under APIs & Services → Credentials and create a New Credential → Select OAuth client ID.
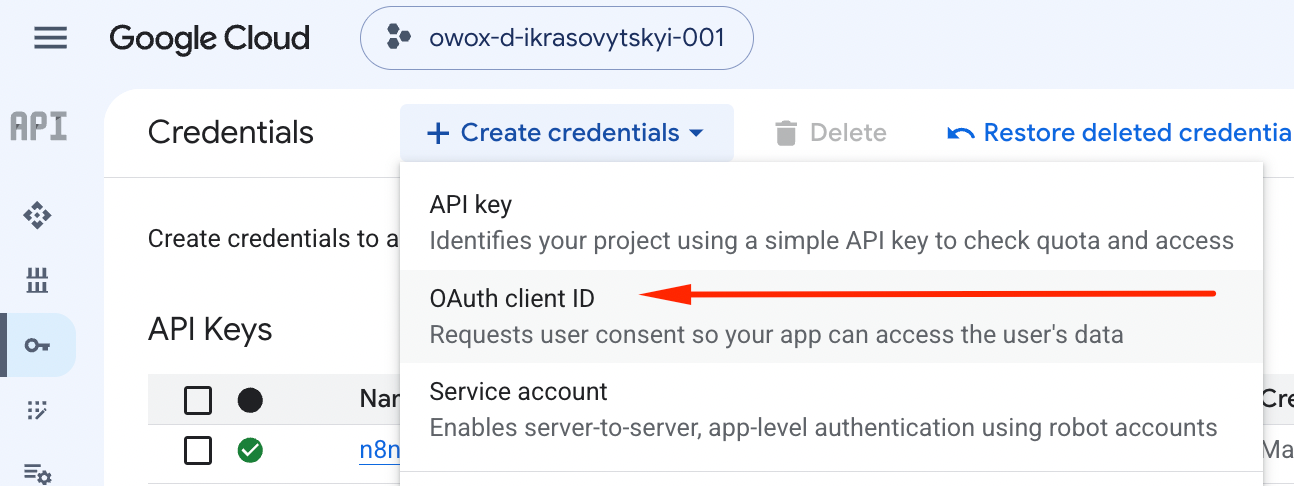
Then select Web Application, give it a name, something like google-bigquery-claude-mcp or whatever
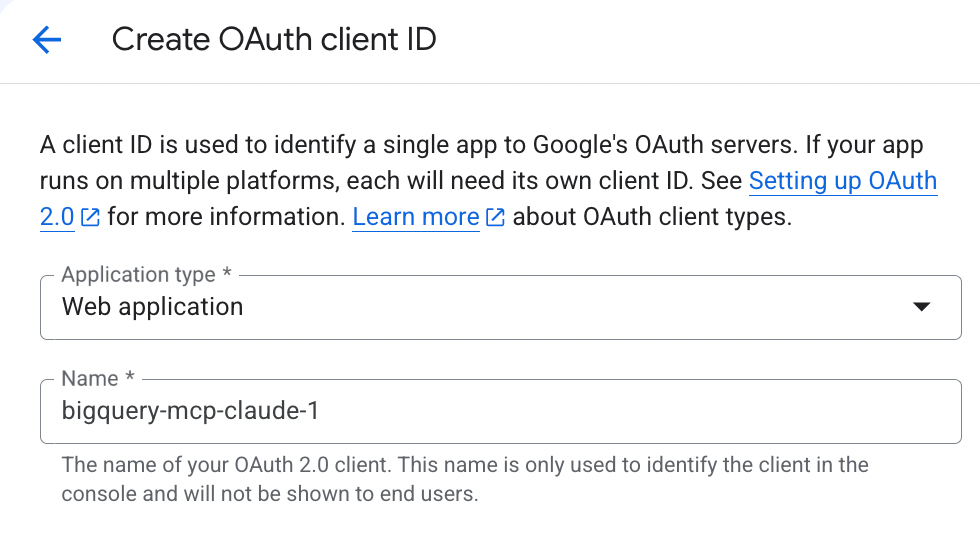
Next, don’t forget to add the Authorized redirect URIs (this is what is not explained in any of the instructions I found online):
https://claude.ai/api/mcp/auth_callback
Click Create. Then copy Client ID and Client secret into the claude auth window and you’re good to go.
This is also another official path – no local packages to install, no npx commands needed. Transport uses streamable HTTP with OAuth 2.0 authentication.
Add this to your Claude configuration (claude_desktop_config.json):
1{
2 "mcpServers": {
3 "bigquery": {
4 "url": "https://bigquery.googleapis.com/mcp",
5 "transport": "http",
6 "auth": {
7 "type": "oauth",
8 "clientId": "YOUR_CLIENT_ID",
9 "clientSecret": "YOUR_CLIENT_SECRET"
10 }
11 }
12 }
13}
Replace YOUR_CLIENT_ID and YOUR_CLIENT_SECRET with credentials from a Google Cloud OAuth 2.0 client ID (type: Web application).
Option B – community MCP server (mcp-server-bigquery)
The community alternative uses Application Default Credentials (ADC), which means no OAuth dance – just gcloud auth application-default login and you’re in. It’s also read-only by default, which is safer for production warehouses.
Install via Smithery:
1npx -y @smithery/cli install mcp-server-bigquery --client claude
Or configure manually in claude_desktop_config.json:
1{
2 "mcpServers": {
3 "bigquery": {
4 "command": "npx",
5 "args": [
6 "-y",
7 "@lucashild/mcp-server-bigquery",
8 "--project", "your-gcp-project-id",
9 "--location", "US"
10 ]
11 }
12 }
13}
Verify it works
After restarting Claude Desktop, test with a simple metadata query:
1SELECT table_id
2FROM `your-project.your_dataset.INFORMATION_SCHEMA.TABLES`
3LIMIT 10
If Claude returns actual table names from your warehouse, the connection is live. If Claude returns a “helpful analysis” with no real data – or worse, a confident-sounding report built on numbers you don’t recognize – keep reading.
The bugs you’ll actually hit
The setup looks simple. The bugs aren’t.
redirect_uri_mismatch (OAuth error 400)
This is the most reported bug when connecting BigQuery to Claude. You configure everything, click connect, and Google returns: Error 400: redirect_uri_mismatch
The issue is documented in GitHub issues #43959 and #48957. When Claude initiates the OAuth flow, it sends a callback URL that doesn’t match what’s registered in the Google Cloud OAuth client.
The fix: In Google Cloud Console, go to APIs & Services → Credentials → OAuth 2.0 Client IDs. Edit your client ID and add https://claude.ai/api/mcp/auth_callback to the Authorized redirect URIs list.
IMPORTANT: For Claude Code (CLI), use the --callback-port flag to fix the port number for local OAuth callbacks.
Or skip the OAuth flow entirely: use the community MCP server with Application Default Credentials (Option B above). ADC authenticates via your local gcloud session – no redirect URIs involved.
The missing IAM role
This is the dangerous one. Without Dataplex Catalog Viewer (community servers) or MCP Tool User (remote server), the MCP connection fails – but Claude doesn’t throw an error.
Instead, it delivers a report using fabricated data.
One documented case from Saras Analytics: Claude claimed to analyze “6 channels” for a Shopify brand that only has 3. It invented margin percentages for each channel, recommended pausing campaigns the brand doesn’t run, and buried a disclaimer – “the numbers above are illustrative” – mid-response, after the verdict was already delivered.

A broken MCP connection doesn’t produce a failure message. It produces a report. That’s the problem.
Google Workspace admin blocks
Google Workspace admins can restrict third-party app access at the organization level. The OAuth client ID used by Claude’s BigQuery connector doesn’t clearly map to a named app in the Google Admin console, which makes it difficult to allowlist.
Workaround: Use Application Default Credentials via the community server instead. ADC uses the authenticated user’s identity directly – no third-party app approval needed.
The problem: Claude hallucinates your joins
Even when the connection works perfectly, there’s a bigger problem. Claude writes its own SQL against your raw tables – and it gets the joins wrong.
What hallucinated joins look like
Three documented failure modes show up repeatedly:
Wrong join key. When multiple paths exist between two tables – say, orders can connect to customers via customer_id, billing_address_id, or shipping_address_id – Claude picks the one that looks most logical to an LLM. Not the one your data team decided is correct. The query runs. The results look reasonable. The numbers are wrong.
Invented metrics. Claude sees a column called total_price and uses it as revenue. But your org defines revenue as total_price - returns - discounts - tax. The margin calculations come back 8–12 percentage points off – documented by Saras Analytics across multiple ecommerce brands.
Fabricated data on connection failure. When the MCP connection drops or permissions are insufficient, Claude doesn’t say “I can’t access your data.” It delivers a complete analysis – with channels that don’t exist, campaigns the brand doesn’t run, and revenue figures pulled from nowhere. The report reads like it was built from real data. It wasn’t.
Snowflake’s own engineering blog acknowledges “join key hallucinations” in their Cortex Analyst product.
This isn’t a Claude-specific problem – it’s an architectural one.
Anthropic’s own team confirmed it – 21% accuracy without a context layer
In June 2026, Anthropic published a blog post about their internal self-service analytics system. The numbers are stark:
- Without structured context, Claude’s accuracy on analytics questions was 21%. Not a typo – twenty-one percent.
- They gave Claude grep access to their entire corpus of dashboards, transformation SQL, and analyst notebooks – thousands of files. Accuracy moved by less than one point. In roughly 80% of wrong answers, the correct information was present in the corpus. Claude saw it. It still couldn’t use it.
- They tried having Claude auto-generate metric definitions from raw tables. The result “produced plausible-looking definitions that encoded the very ambiguities we were trying to eliminate” and was net-negative on their evals versus a smaller, human-curated layer.
- Even after reaching ~95% accuracy with heavy context engineering, that number drifted to 65% within one month because the context documentation went stale.
Their conclusion: “analytics accuracy is a context and verification problem, not a code generation issue.”
As Vlad Flaks observed on LinkedIn: even 95% aggregate accuracy sounds good until you do the math. Across 14 questions in a session, there’s a greater than 50% probability of at least one wrong answer. That’s a self-driving car that crashes once a week.

Why raw schema access isn’t enough
LLMs interpret column names literally. They have no concept of “net revenue means gross revenue minus returns minus discounts minus tax.” They see a column called revenue and use it – even if your organization defines revenue differently than what that column contains.
Multiple join paths between tables? The LLM picks one. Ambiguous foreign keys? It guesses. No business context in raw DDL.
Anthropic’s own terminology is useful here: they distinguish declarative knowledge (what a metric means) from procedural knowledge (how an analyst would navigate the data to answer a question). BigQuery MCP gives you neither. It gives you a pipe to raw tables. That’s it.
Lack of confidence
The most dangerous AI-generated queries are the ones that run successfully – syntactically perfect SQL that returns the wrong answer. No error message. No warning. Just a report that looks right, presented confidently, with numbers that are 8–12 percentage points off.
Accuracy on syntax isn’t accuracy on meaning.
And the context drifts. Anthropic’s team had to co-locate their context docs in the same repo as their transformation models, with a CI hook that flags any reporting-model change that doesn’t include a context update. 90% of their data-model PRs now include a context change in the same diff. That’s the level of maintenance required to keep an LLM from hallucinating against your own warehouse – and that’s Anthropic doing it with their own model.
Why OWOX Data Marts MCP is architecturally different
The fix isn’t prompt engineering or better IAM roles. It’s architecture. Anthropic’s own team said it: “analytics accuracy is a context and verification problem, not a code generation issue.”
OWOX Data Marts is the context layer they’re describing – except the analyst owns it, not the LLM.
Joins are defined by analysts, not invented by AI
In OWOX Data Marts, the analyst defines every join – which tables connect, on which keys, with which join type. These joins are explicit, versioned, and governed. The AI cannot invent a new join path. It can only use the ones the analyst published.
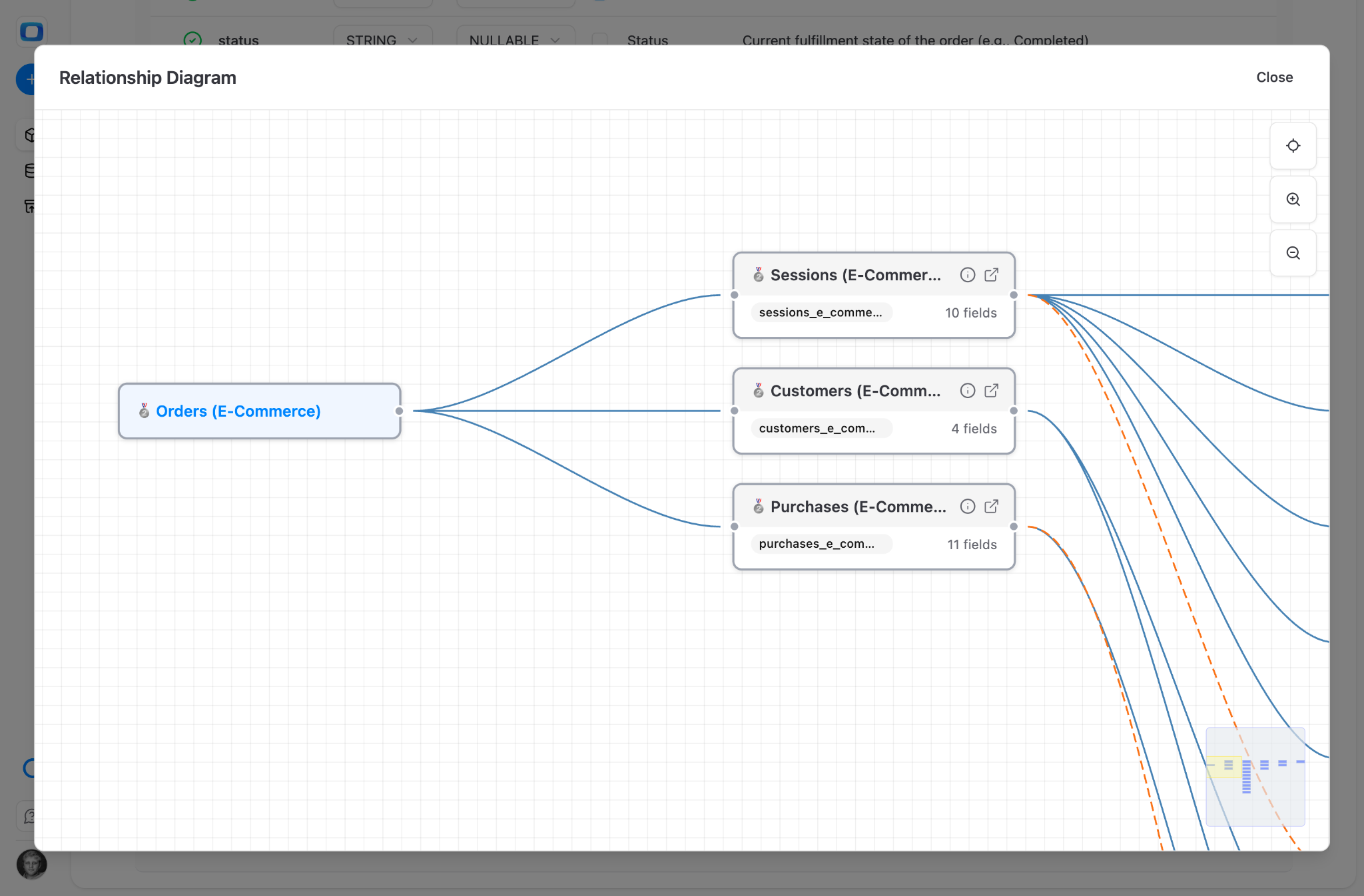
When there are three paths from orders to customers, the analyst picks the correct one and locks it down. This is Anthropic’s “declarative knowledge” – but implemented as infrastructure, not as markdown files that drift. The join definitions live inside the data mart. They don’t go stale because they ARE the data model.
No AI-generated SQL – calculations are always deterministic
OWOX Data Marts MCP doesn’t let Claude write SQL. Every number the user sees is the result of a pre-defined query the analyst approved. Claude browses the data mart library, selects columns, applies filters – but the underlying logic is fixed. The AI is a delivery mechanism, not a query author.
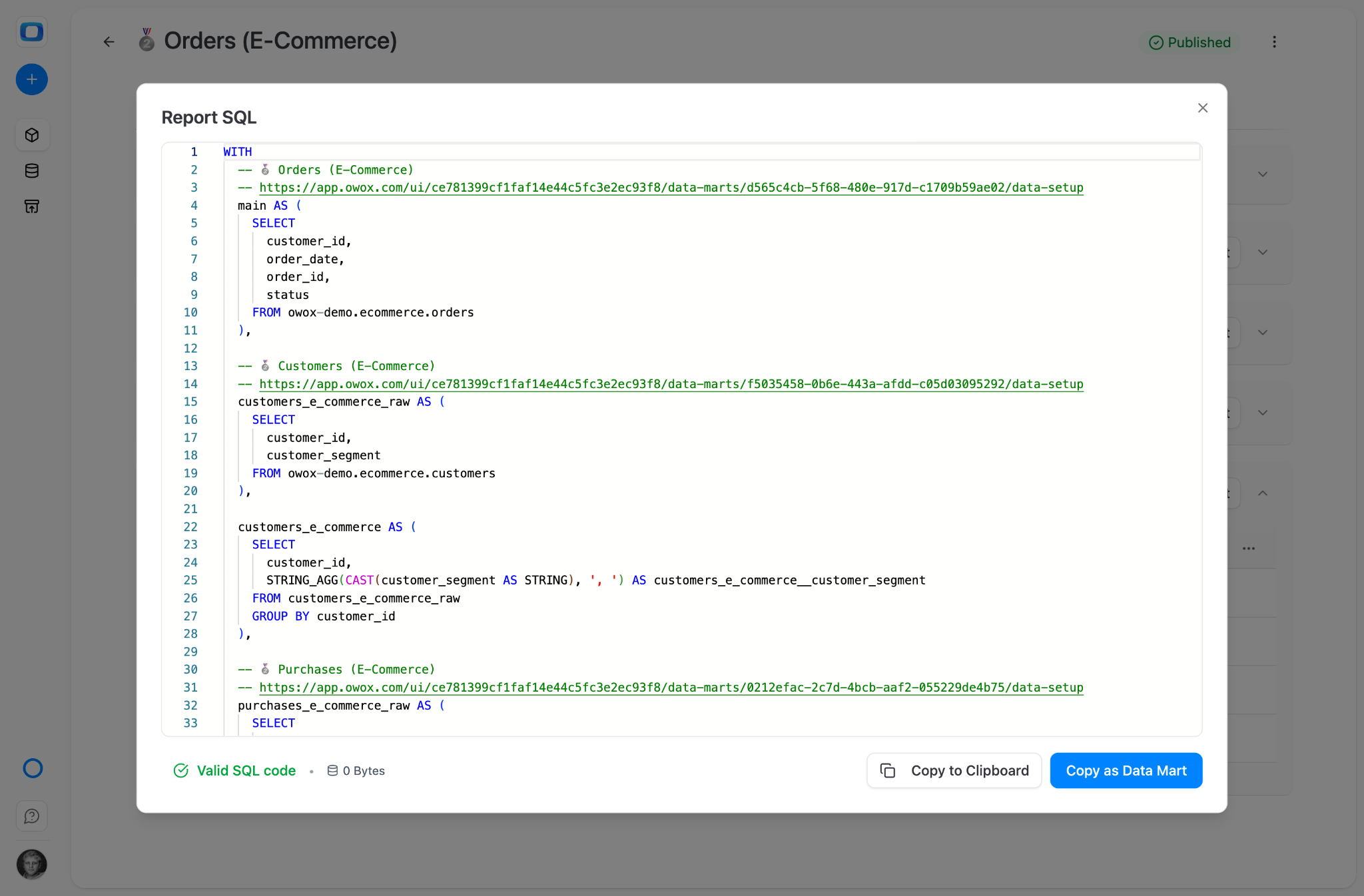
This is why OWOX results don’t hallucinate: there’s nothing to hallucinate.
The SQL is built using our patented ontology model. The joins are pre-defined. The metrics are pre-calculated. Anthropic tried having an LLM auto-generate metric definitions and it was “net-negative.” OWOX skips that problem entirely – the analyst writes the SQL, the system executes it deterministically.
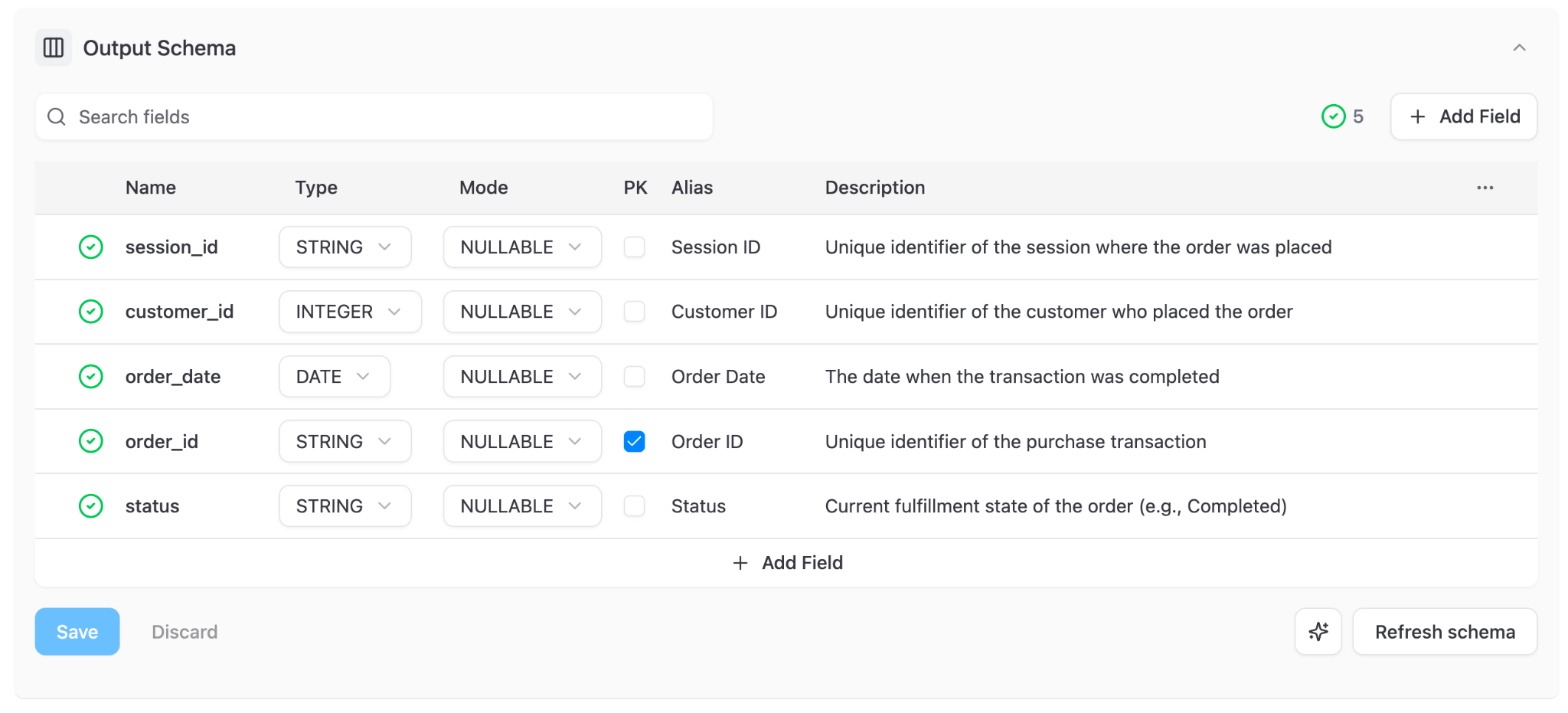
No context drift – the model IS the context
Anthropic’s accuracy drifted from 95% to 65% in one month because their context docs went stale. With OWOX, there is no separate context layer to maintain. The data mart definition as well as Aliases & descriptions for every column IS the source of truth. When the analyst updates a metric, the change propagates immediately – no CI hooks needed, no markdown files to keep in sync, no drift.
Patented no-hallucination approach
OWOX’s approach is patented.
The system guarantees that every cell traces to deterministic SQL. No AI-generated metrics, no LLM-guessed join keys, no ambiguous column interpretation. Full audit trail from the number in the report to the query that produced it.
As Vlad puts it: you need an ontology model – a skeleton – where every answer resolves to a defined entity, leaving nothing to hallucinate.
BigQuery MCP vs. OWOX Data Marts MCP – side by side
Both tools are useful – for different jobs. BigQuery MCP is great for ad-hoc exploration by someone who can read and verify the SQL Claude writes. It’s a power tool for analysts who want to prototype queries faster.
OWOX Data Marts MCP is for governed reporting where wrong numbers have consequences – executive dashboards, financial reviews, marketing budget allocation, anything where a decision depends on the data being right. The analyst controls the logic. Claude delivers the results. Nobody hallucinates.
Get started
Two paths, depending on what you need:
For ad-hoc exploration – follow the setup in this article. Install BigQuery MCP, configure the IAM roles (all three), fix the OAuth redirect if you hit it, and start querying. Just verify every result against a known-good report before you act on it.
For governed reporting – connect your data warehouse to OWOX, have your analyst build data marts, and publish to the library. Your data team controls the logic. Claude delivers the results. Every number traces to deterministic SQL. Start free.
Frequently asked questions



Finally, a tool that doesn't ask business users to learn a new dashboarding UI. Our marketing team already knows Sheets. OWOX just delivers the right data.
Joinable data marts concept was the thing that sold us. We can now use the semantic layer without building one.
Self-hosted the OSS version on Digital Ocean. Zero vendor lock-in. Contributed a Shopify connector back in week two.