
The analyst’s guide to killing the reporting backlog (without hiring)
Intake forms, Scrum, and hiring don't fix the backlog. A joined data mart library does. Here's how 3-5 marts clear 40-60% of requests.

.png)
You know the number. Maybe it's 200 open tickets. Maybe it's a Slack channel with 47 unread messages, each one starting with "hey, quick question." Maybe it's the spreadsheet your team lead maintains – the one nobody talks about in standups – where every row is a request that won't get touched this quarter.
The reporting backlog is the single most common symptom of a data team under pressure. It drives analyst burnout, blocks strategic work, and turns your best people into reactive report factories. And if you're reading this, you've probably already tried the obvious fixes: intake forms, sprint planning, request prioritization, maybe even a new hire. None of them worked – or they worked for a month, then the reporting backlog filled back up.
That's because the reporting backlog isn't a process problem. It's an architecture problem. And the fix isn't better queue management – it's to automate reporting delivery so the queue empties itself.
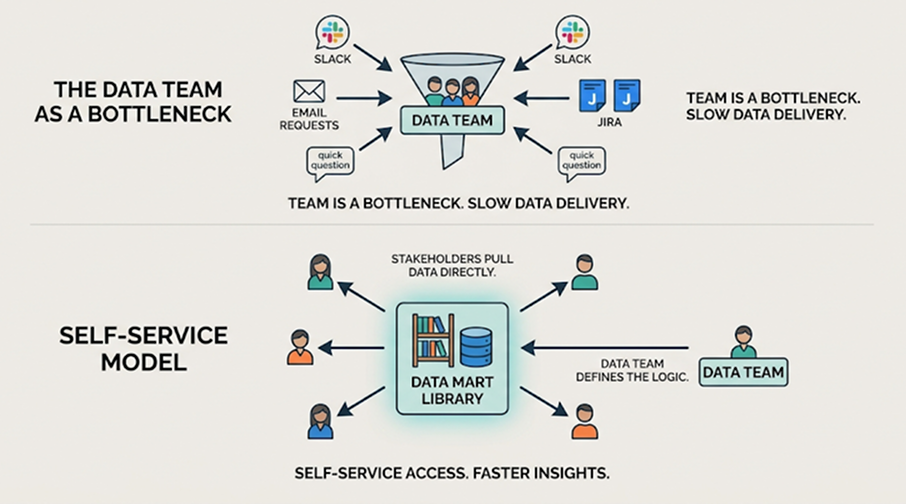
Why fixing existing process don't fix it
You've tried the process solutions. Here's why they didn't work.
Ticketing systems and intake forms
Standardizing requests helps triage. You stop getting "hey, can you pull something for me?" and start getting structured asks with deadlines and business context. That's a real improvement – for about two weeks.
The problem is that intake forms don't reduce volume. You still have the same number of questions. You just organized the queue. The bottleneck moves from "which request first?" to "when will the analyst get to it?" The ad-hoc reporting burden stays exactly the same – it's just better documented.
Scrum for data teams
Sprint planning for analytics sounds right. Estimate the work, commit to a scope, protect the team's time. Some teams even run two-week sprints with dedicated "analytics office hours" for stakeholders.
But ad-hoc requests don't respect sprints. When the CMO asks for campaign performance before the board meeting, it doesn't wait for next sprint. When finance needs a reconciliation number by Friday, it jumps the queue. Scrum organizes the work; it doesn't eliminate the work that shouldn't be manual in the first place.
Hiring another analyst
The most common response – and the most expensive band-aid. You add capacity. Demand grows to match it. Every new analyst who publishes reports creates new consumers who will ask for refreshes, variations, and "one more column." I've watched teams go from 2 analysts to 6 and still have a backlog – because each new analyst also created new stakeholders who discovered they could get data if they just asked.
The backlog scales with the team. That's not a hiring problem. That's a design problem.
The backlog is an architecture problem, not a process problem
Here's what the post-mortem always misses.
Every report in your backlog is a bespoke, manually-assembled artifact. The analyst writes SQL. Runs the query. Exports the result. Formats it. Delivers it via Sheets or Slack or email. Then repeats the whole thing next week, next month, next quarter – often with slightly different parameters.
The backlog exists because the delivery model is one analyst → many stakeholders, manual, and non-reusable. Every question gets a handmade answer. Every variation is a new ticket.
The fix isn't better process on top of manual delivery. It's removing the manual delivery entirely. Make the analyst's work reusable – define the logic once, let everyone else pull from it – and the backlog disappears by design.
The backlog exists because every report is handmade. Make the logic reusable, and the queue empties itself.
This is the shift from analyst-as-bottleneck to analyst-as-architect. The analyst stops being reactive – pulling data on demand – and becomes strategic: defining how data is delivered across the organization. Same skills, higher leverage, radically less repetitive work.
The data mart library – define once, self-serve forever
Here's the architecture that eliminates the manual delivery model.
What a data mart library is
A Data Mart is a governed, analyst-defined dataset that answers a business question correctly. The analyst writes the SQL (or points to an existing table or view), defines the schema – business-friendly aliases, descriptions, join keys – sets access controls, and publishes it to the library.
The data mart is a reusable artifact, not a one-off export. It refreshes on a schedule. It's versioned. It's governed. And anyone with access can pull from it without filing a ticket.
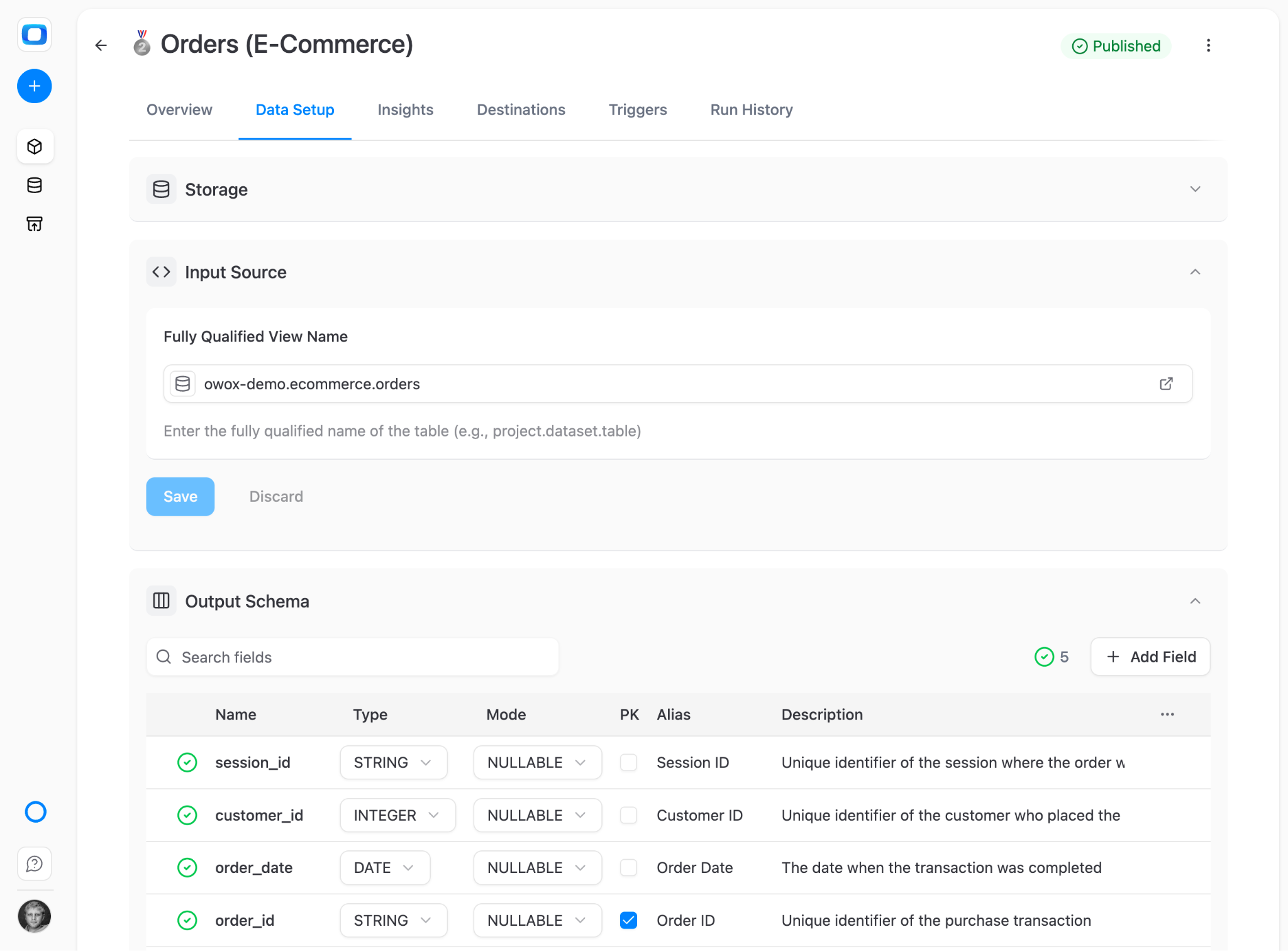
How business users self-serve from it
Business users open Google Sheets and browse the Data Mart library via the OWOX extension. They pick columns – including joined columns from related data marts (the analyst defined the join keys, so the joins are safe). They apply filters. They pull data. The Sheet refreshes on schedule.
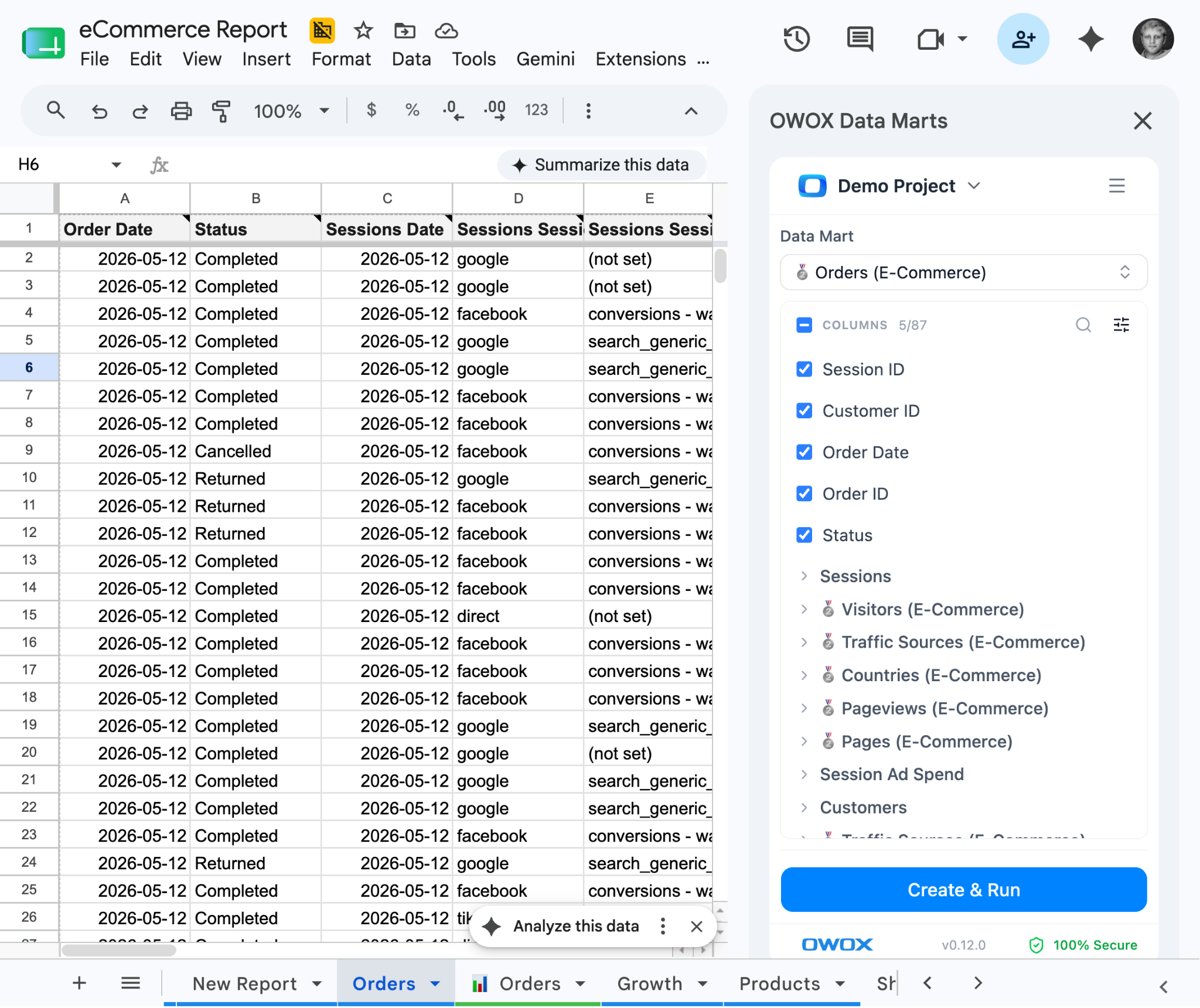
No SQL. No tickets. No "hey, can you refresh this?" The analyst's survival guide to ad-hoc requests becomes unnecessary – because the requests stop.
What this does to the backlog
Every data mart the analyst publishes removes an entire class of requests – not one ticket, but every variation of that question, forever. "Revenue by channel this month" becomes a data mart. Next month, the business user refreshes it themselves. "Add last quarter" – they filter it themselves. "Break it by region" – they pick the column themselves.
The backlog shrinks by categories, not by individual tickets. And the analyst's time shifts to the work that actually requires human judgment: metric definitions, variance diagnosis, business-logic mapping, and stakeholder translation.
But what if business users break things?
The most common objection from data leaders – and the most important one to address directly.
The analyst controls the logic
Business users can't change the SQL. They can't alter the metric definition. They can't modify the join keys. They can only filter and select from what the analyst made available. The analyst is the governor – not the delivery person, but the person who decides what's safe to self-serve and what isn't.
This is the difference between "business users have access to the warehouse" (terrifying) and "business users browse a curated library of analyst-approved datasets" (governed). The data mart management layer is the boundary.
Every number traces back
Full SQL audit trail. Every cell in the Sheet traces to a query the analyst approved. No hallucinations, no AI-generated metrics, no business user computing their own version of revenue in a rogue spreadsheet. One source of truth, governed by the data team.
The irony: most data leaders worry that self-service will create chaos. In practice, the chaos already exists – it's the shadow spreadsheet stack that grew because the official channel was too slow. A governed data mart library replaces the chaos with a controlled system. It's not less governance; it's more governance, delivered faster.
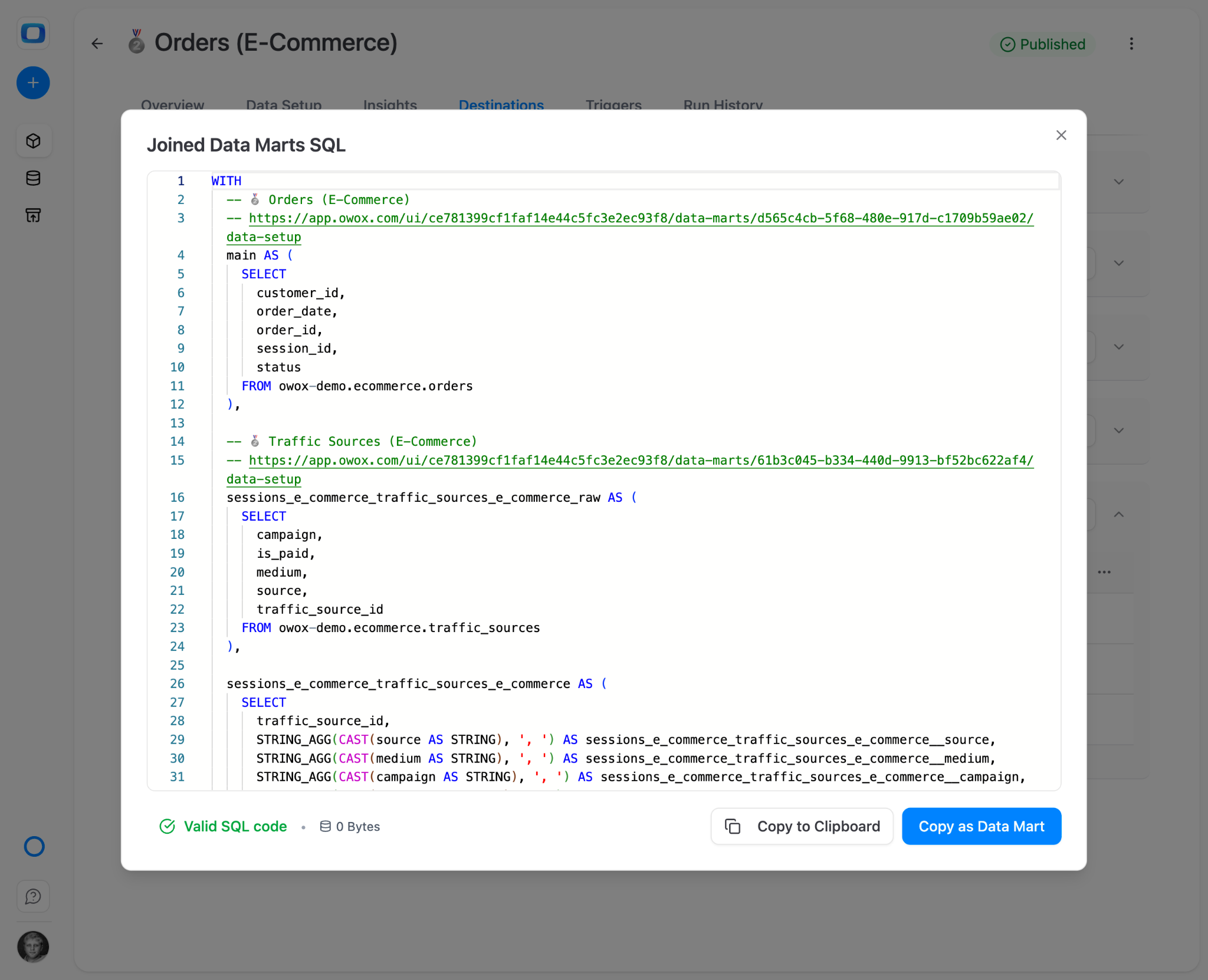
Start with a few data marts. Join them. Self-service in 5 minutes.
You don't need to boil the ocean. Start with the entities your team already asks about every week.
Ecommerce example: Create three data marts – Products, Orders, Customers. Join them on shared keys (order_id, customer_id). Now any stakeholder can pull "revenue by product category for returning customers last quarter" without writing SQL or filing a ticket. Three data marts, joined – and an entire class of ecommerce questions is self-served.
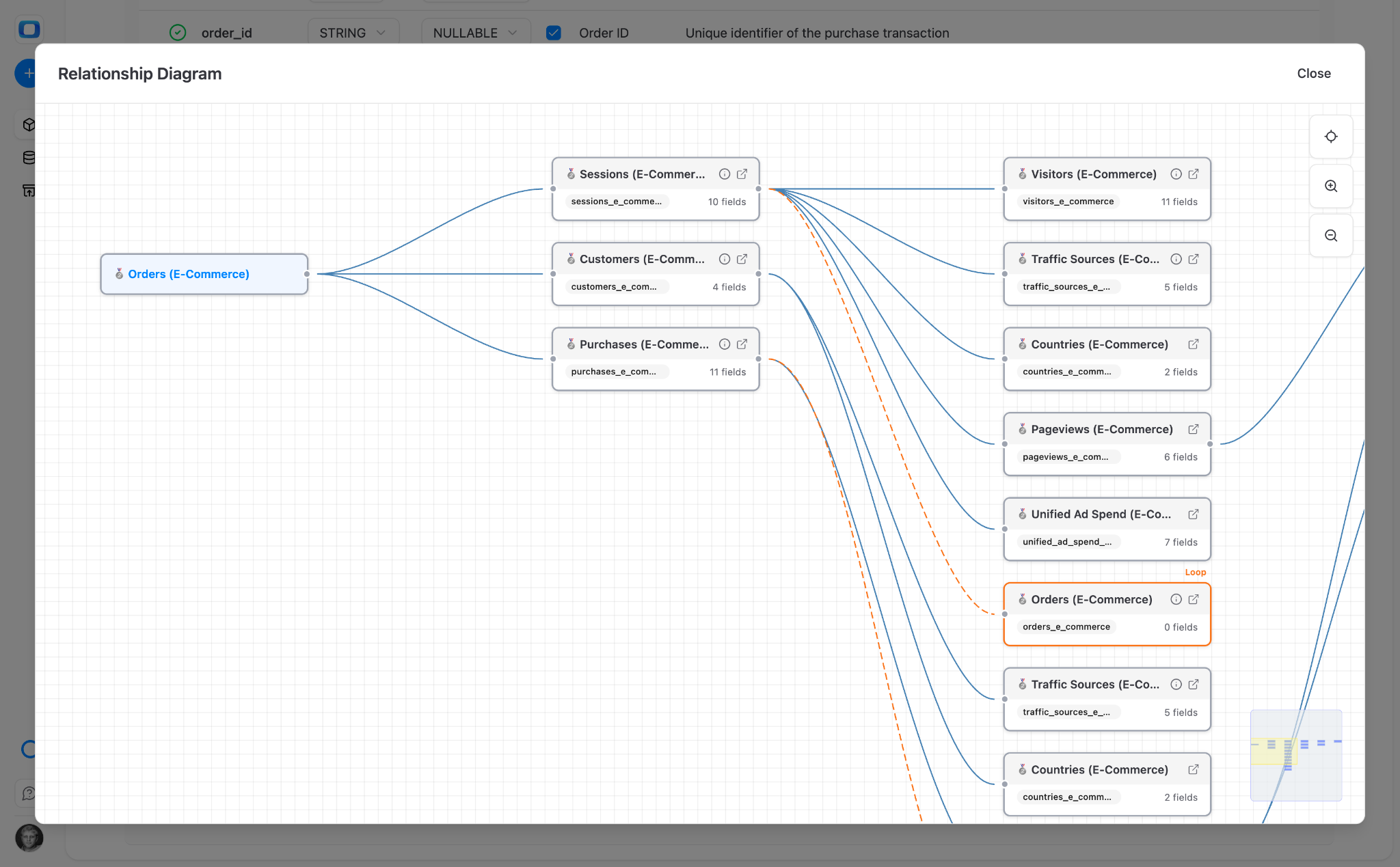
Marketing example: Sessions, Pageviews, Pages, Visitors, Users, Customers, Events. Join them on user_id and session_id. The marketing team stops asking "can you pull traffic by landing page with conversion?" – they pull it themselves from joined data marts in Google Sheets.
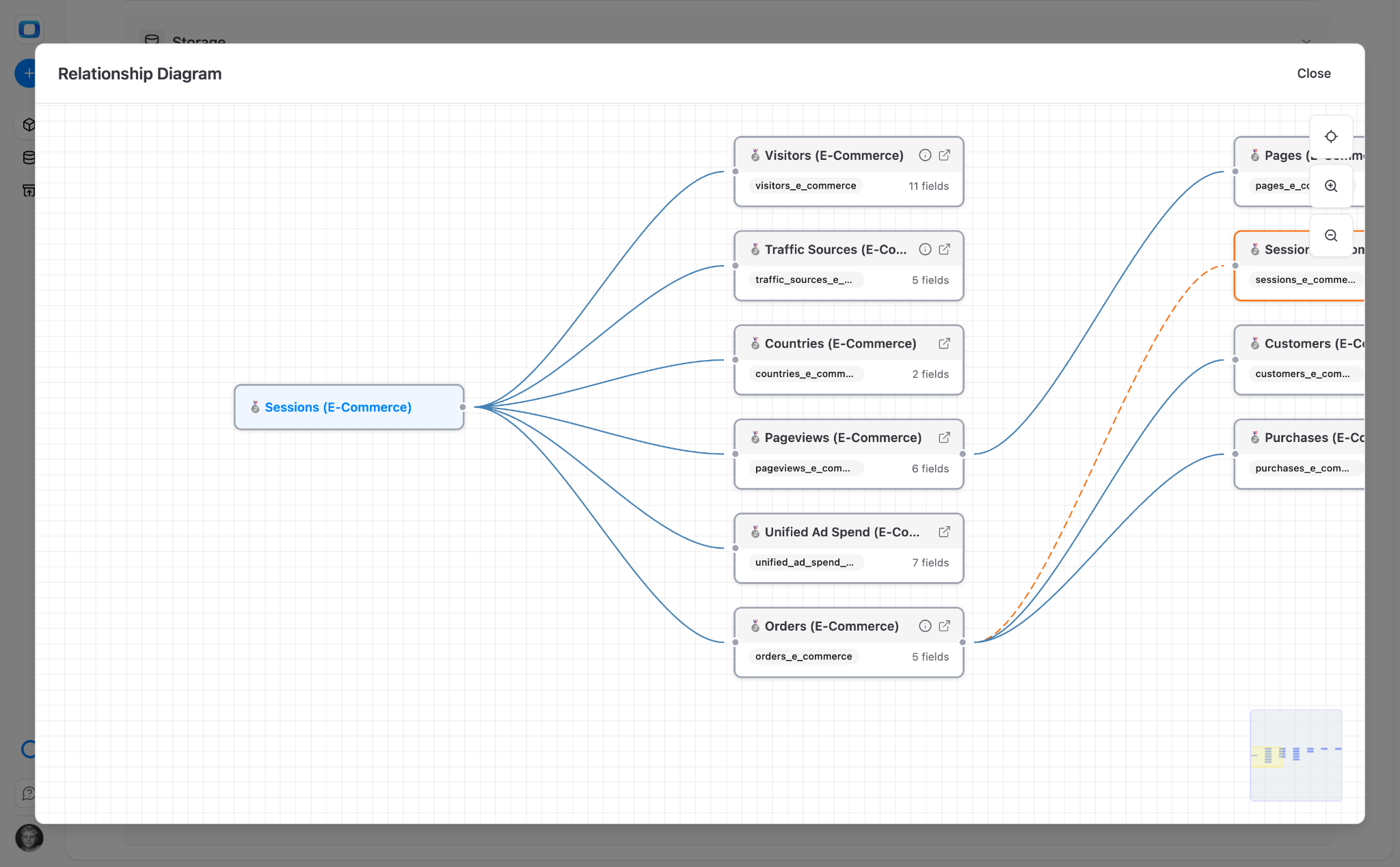
The power isn't in one data mart – it's in the joins. When the analyst defines how Products relates to Orders relates to Customers, every downstream question that crosses those entities is answered automatically. Each join multiplies the number of questions that are self-servable.
Most teams find that 3–5 joined data marts clear 40–60% of the backlog – because the most-requested reports are just different views of the same underlying entities. "Revenue by channel," "revenue by region," "revenue by product" – all answered by the same joined data mart library.
The ROI math: If each ad-hoc request takes 2–4 hours, and your top 5 entity groups generate 80% of the requests, a joined data mart library saves your team 20–40 hours per week. That's a full-time analyst's worth of capacity – without hiring. The automated reporting layer pays for itself before the first month ends.
That's what it means to kill the backlog without adding headcount. The analyst's role doesn't shrink – it shifts from delivery to architecture. From "can you pull this?" to "let me design the system that answers every version of that question automatically."
Start free → Build your first joined Data Mart library and watch the backlog empty itself.
Frequently asked questions



Finally, a tool that doesn't ask business users to learn a new dashboarding UI. Our marketing team already knows Sheets. OWOX just delivers the right data.
Joinable data marts concept was the thing that sold us. We can now use the semantic layer without building one.
Self-hosted the OSS version on Digital Ocean. Zero vendor lock-in. Contributed a Shopify connector back in week two.